If you’re chatting with someone, and they tell you “aslkjeklvm,e,zk3l1” then they’re speaking gibberish. But how can you teach a computer to recognize gibberish, and more importantly, why bother? I’ve looked at a lot of Android malware, and I’ve noticed that many of them have gibberish strings either as literals in the code, as class names, in the signature, and so on. My hypothesis was that if you could quantify gibberishness, it would be a good feature in a machine learning model. I’ve tested this intuition, and in this post I’ll be sharing my results.
What is a Markov chain?
You could just read Wikipedia, but ain’t no one got time for that. Simply put, you show it lots of strings to train it. Once it’s trained, you can give it a string and it’ll tell you how much it looks like the strings it was trained on. This is called getting the probability of a string.
Markov chains are quite simple. The code I used is here: https://gist.github.com/CalebFenton/a129333dabc1cc346b0874407f92b568
It’s loosely based on Rob Neuhaus’s Gibberish Detector.
The Experiment
I’ve been trying to improve the model I use in the Judge Android malware detector. It would have been a lot easier to just create some Markov based features, throw them into the model, and roll with it. But I wanted to be scientific. Everyone thinks science is all fun and rainbows, but thats only in the highlight reel. The real bulk of science, the behind the scenes footage, is tedious and hard. In order to make a data-driven decision about which features worked best and if they helped at all, I took lots of notes of my experiment and preserved all the data. Hopefully, it’s helpful to others.
I started by collecting all of the strings from my data set. For reference, the data set contained ~185,000 samples, about half of which are malicious. Malicious apps are from all over, but many are from VirusTotal with 20+ positives. Benign apps are possibly more diverse and contain strings in several languages.
After collecting strings, I trained a Markov model on the strings in the benign apps. For each occurrence of a string, I trained the model on that string. This model would “know” what legitimate, non-malicious strings were probable. Then, I calculated the probability of each benign string and plotted the distribution on a curve.
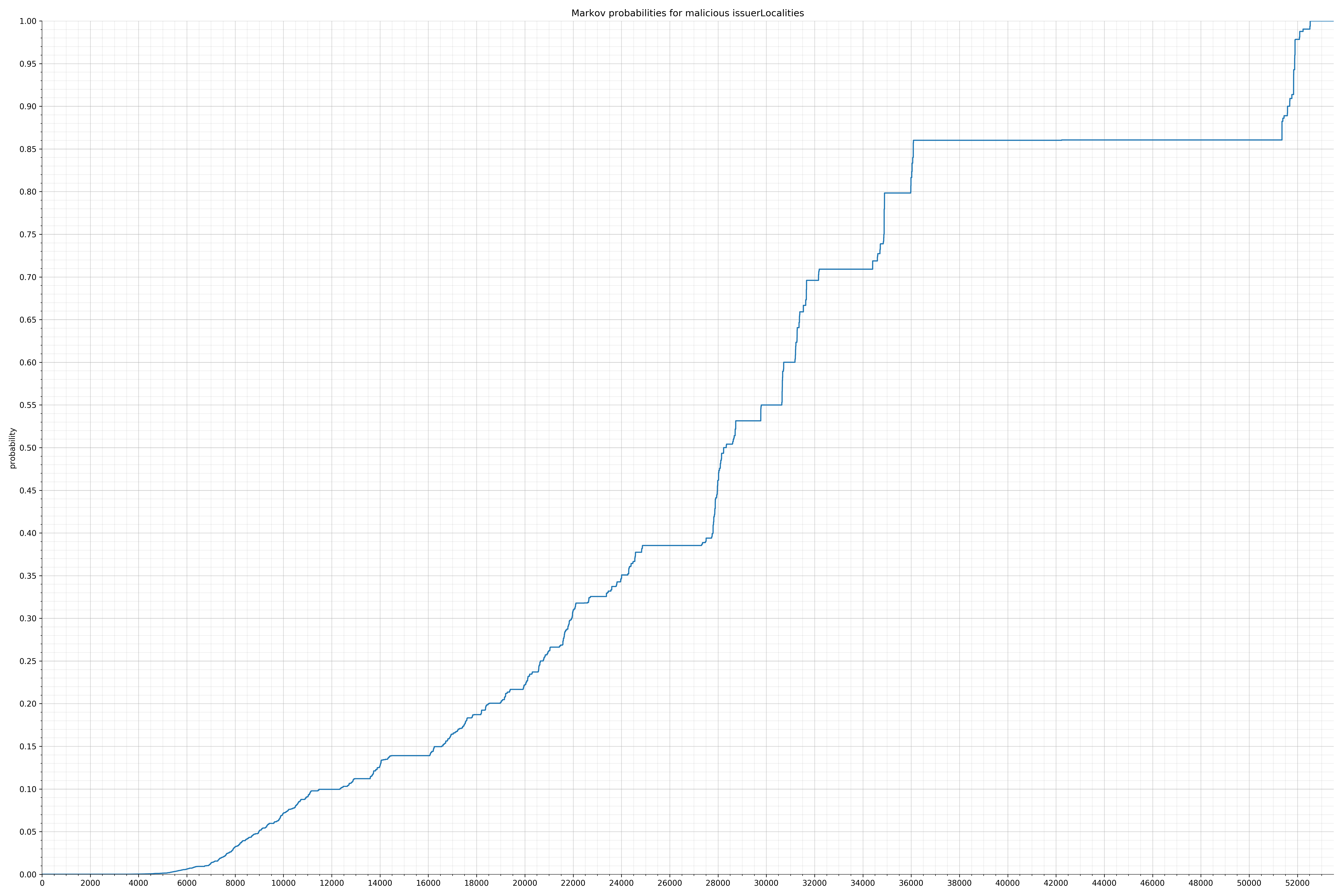
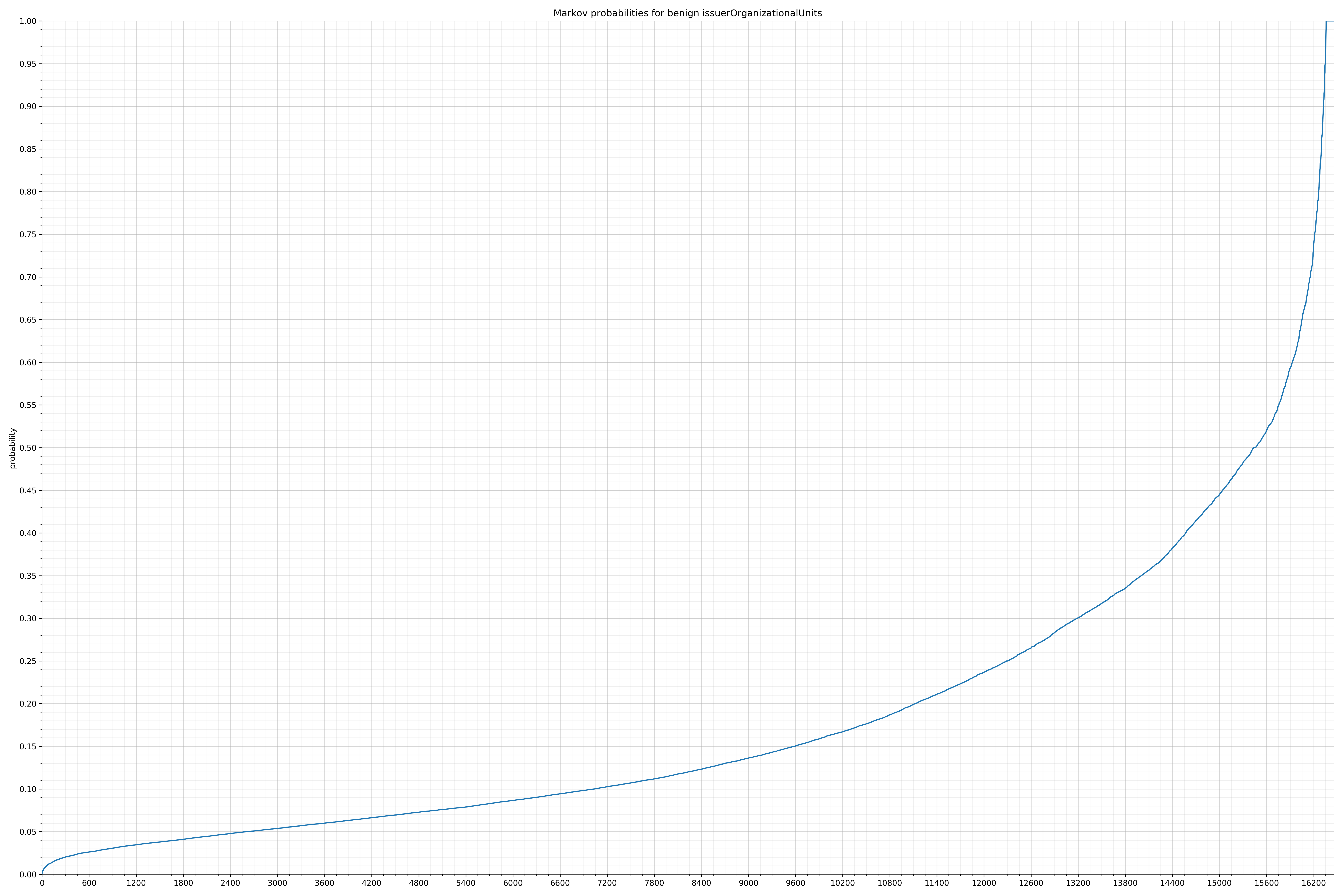
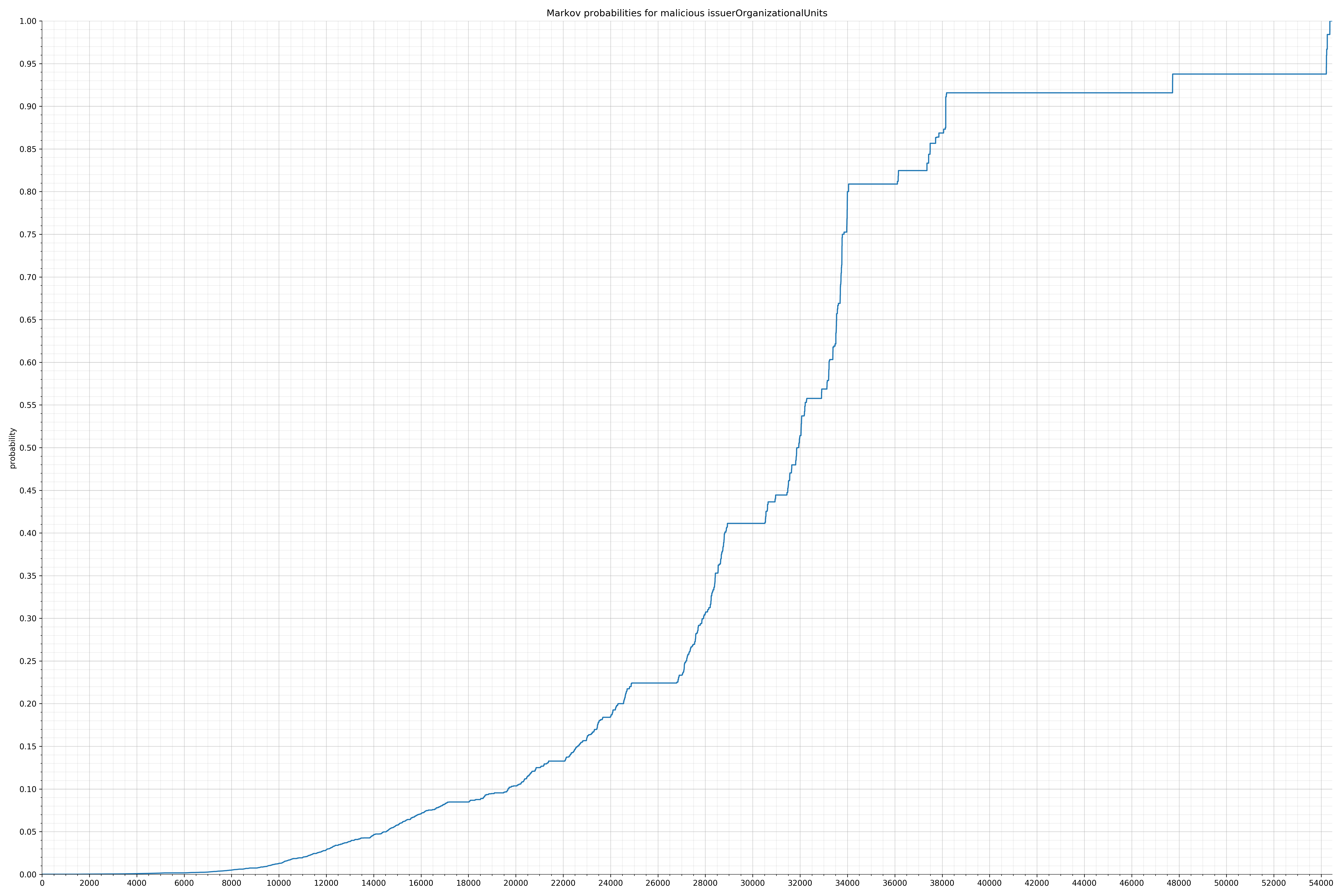
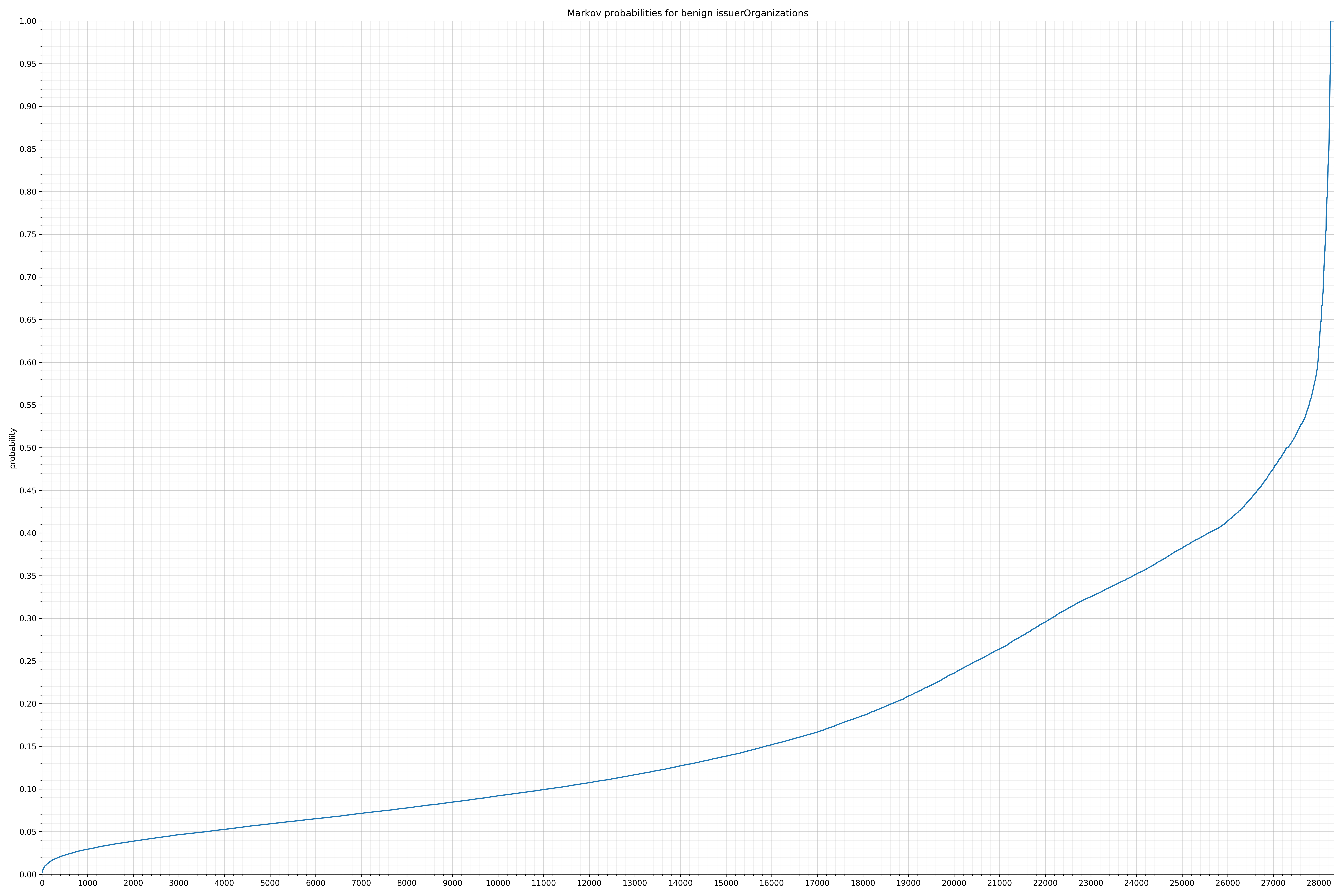
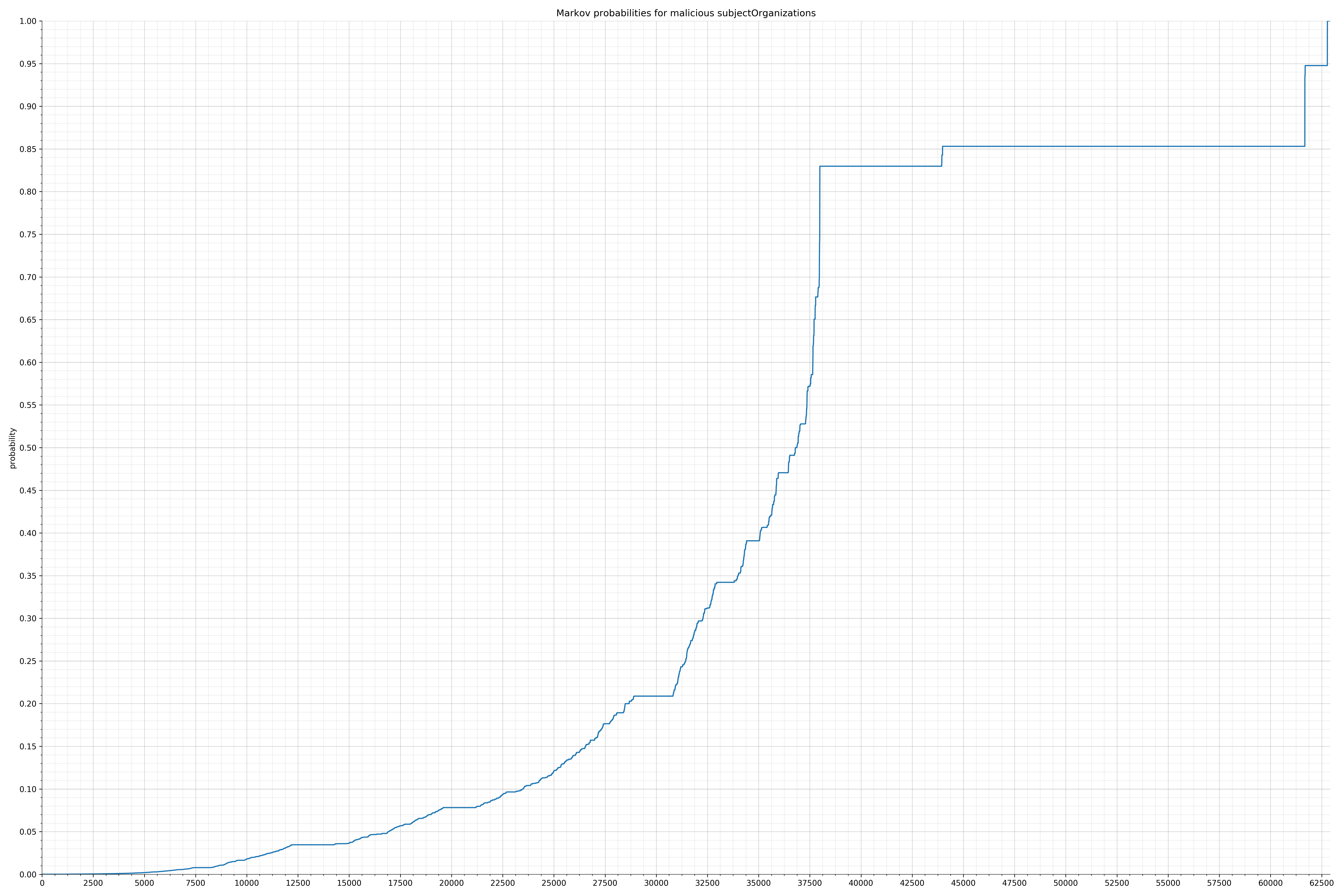
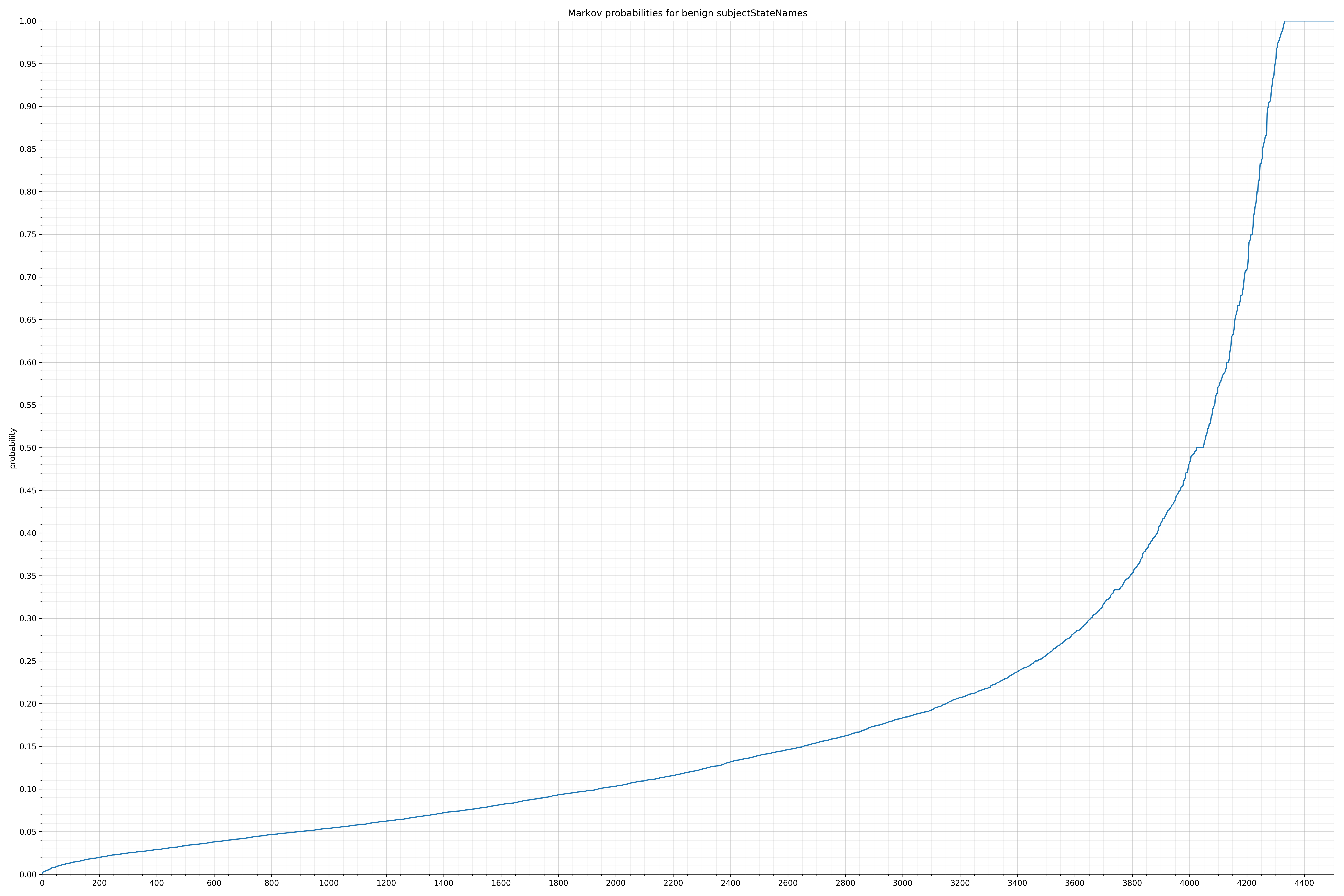
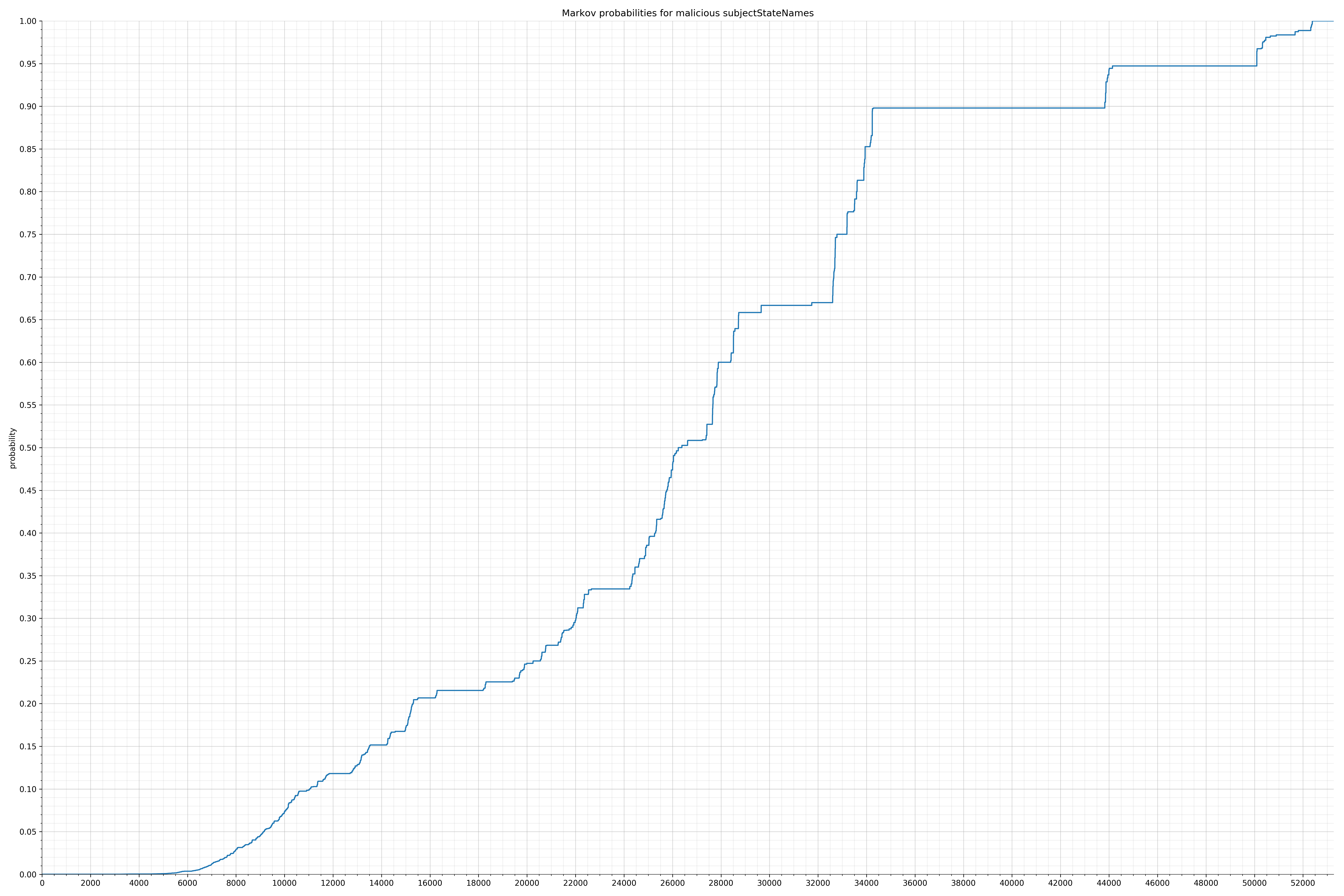
Finally, I used the Markov model trained on the benign strings to calculate probabilities of all the malicious strings and also plotted them. Before I spent time writing any code for features, I wanted to know if there was even a significant difference in probability distribution. If there wasn’t, I would have probably written the code anyway because this is how I spend my weekends, but it turns out there was a significant difference and I felt much more confident the features would be useful.
The Markov chain was configured to use bigrams and strings were tokenized depending on their category. Below are the patterns used:
1 |
|
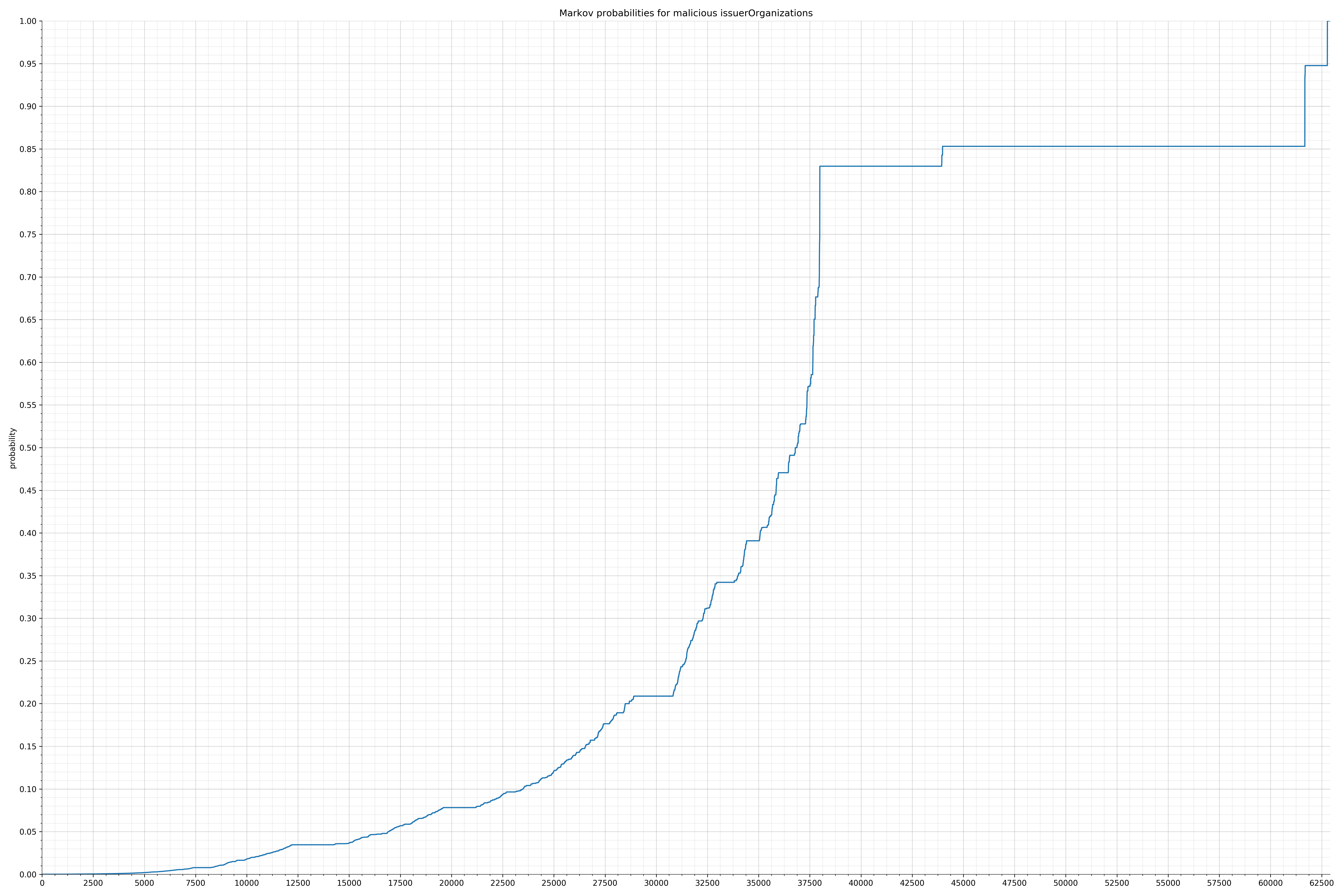
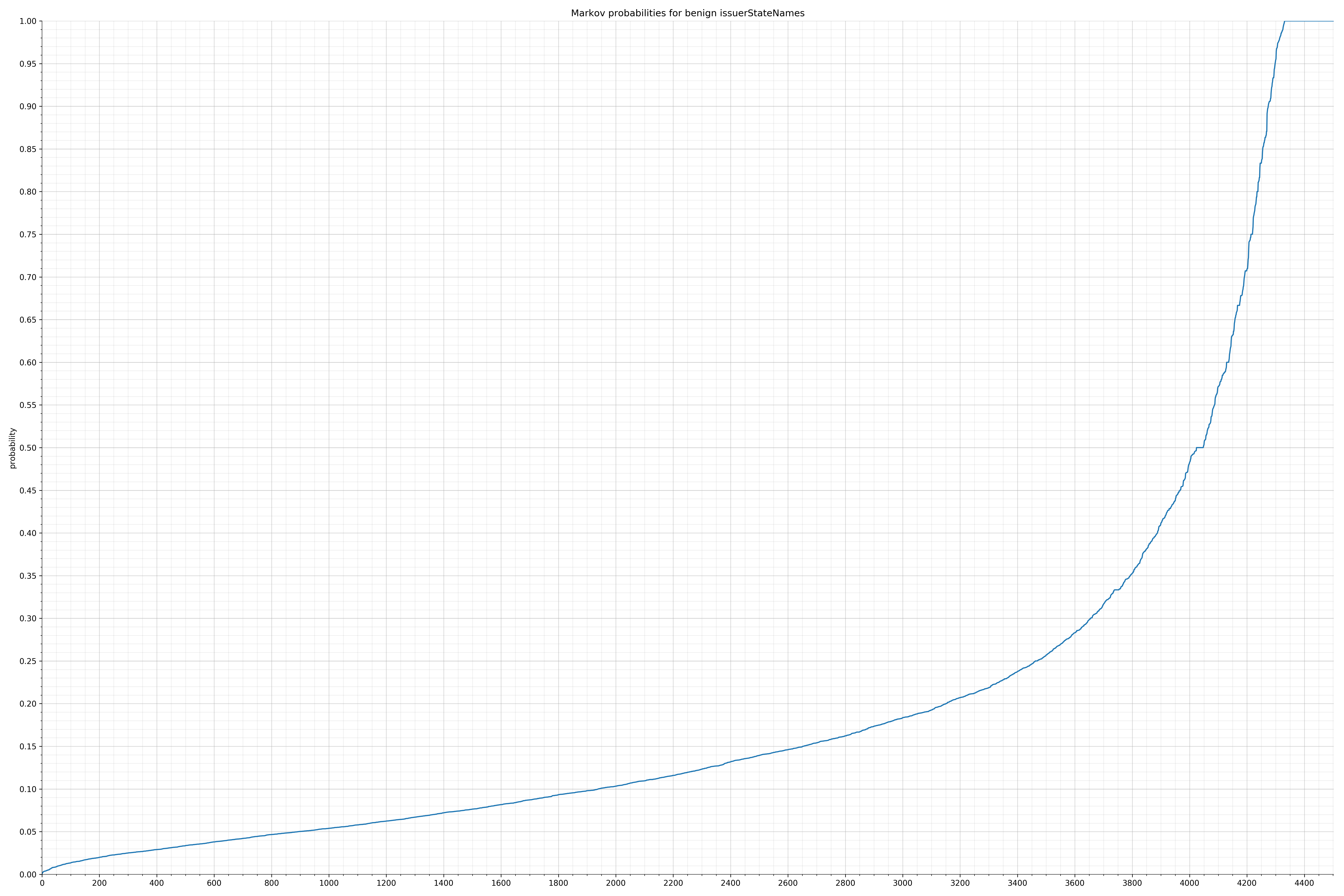
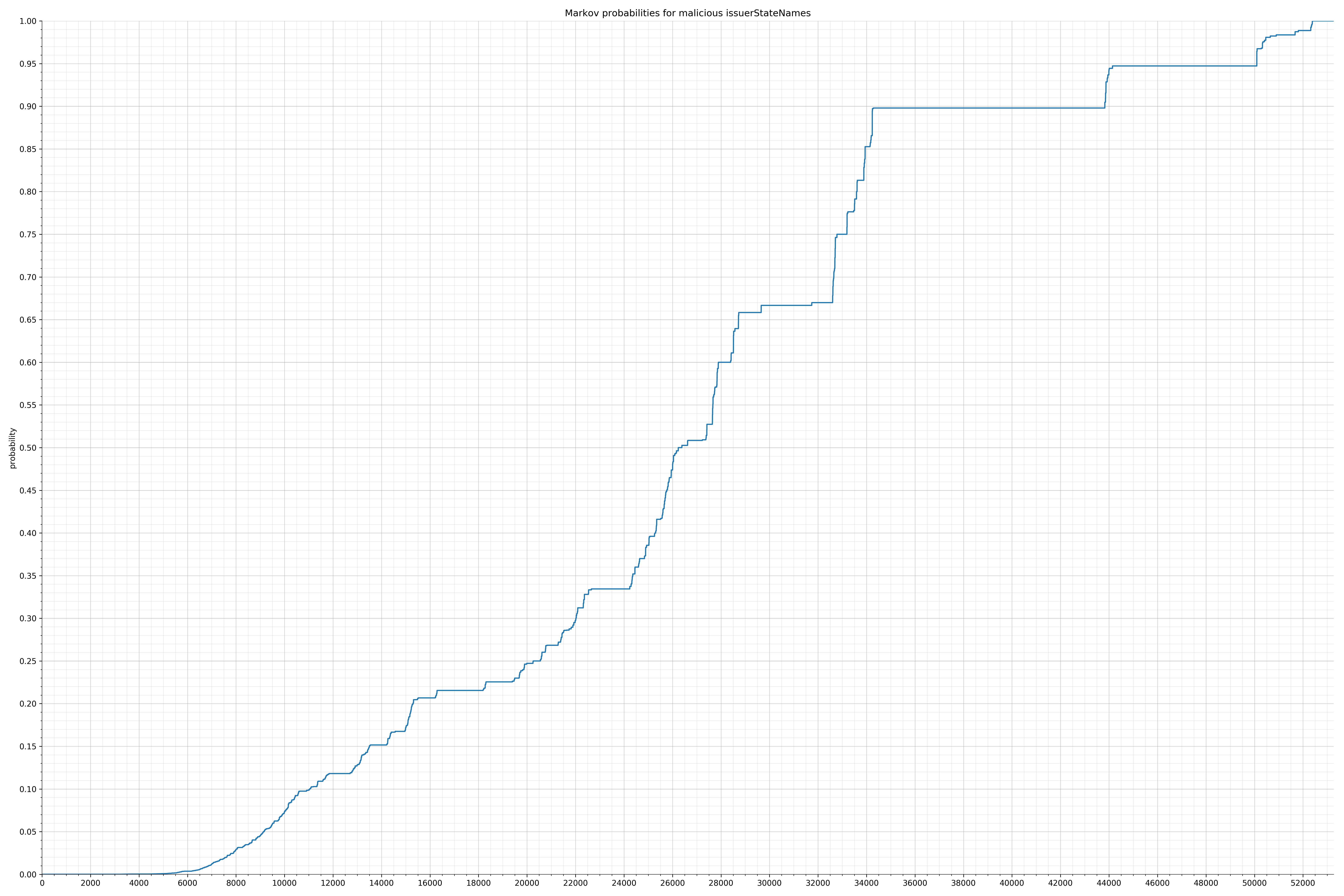
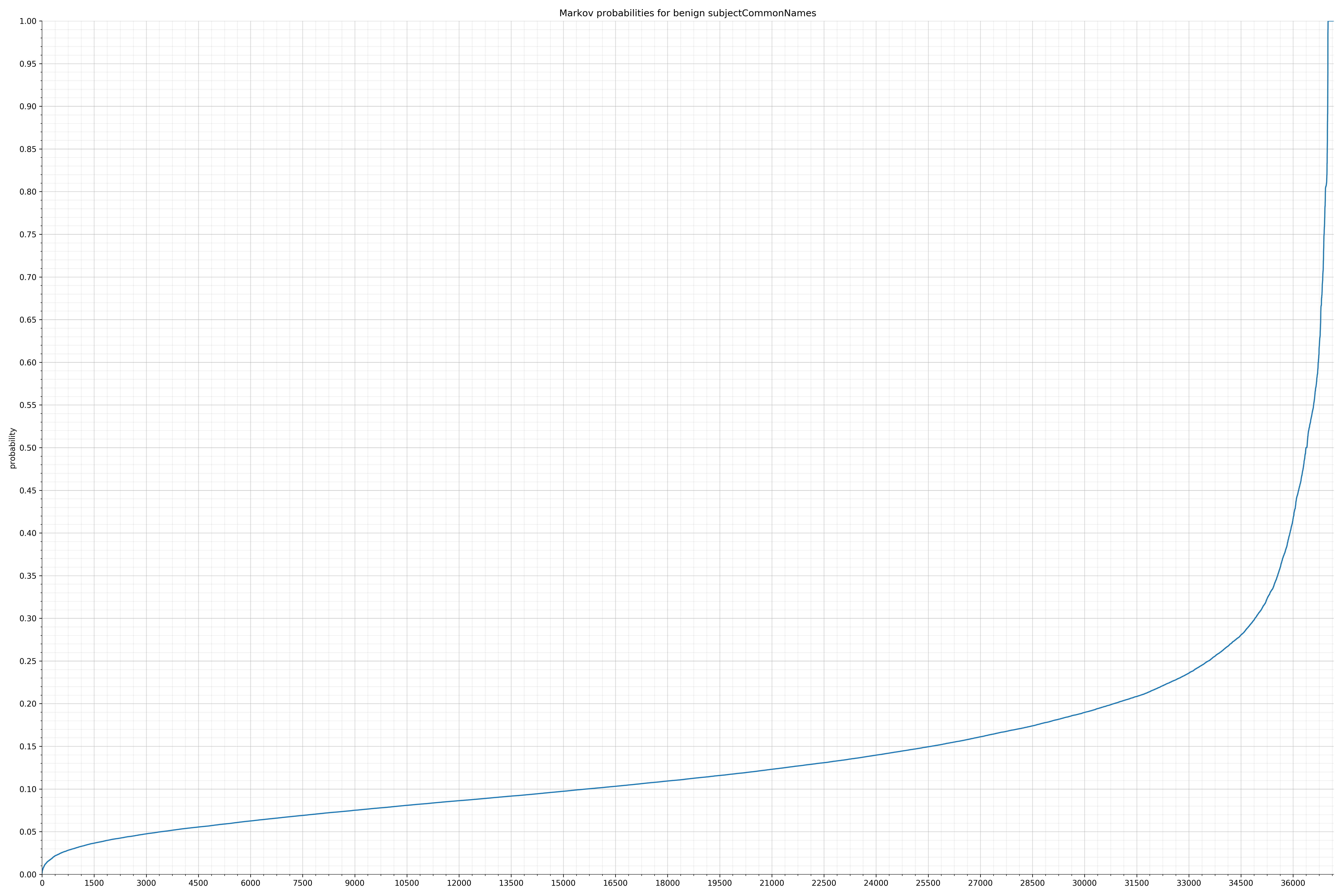
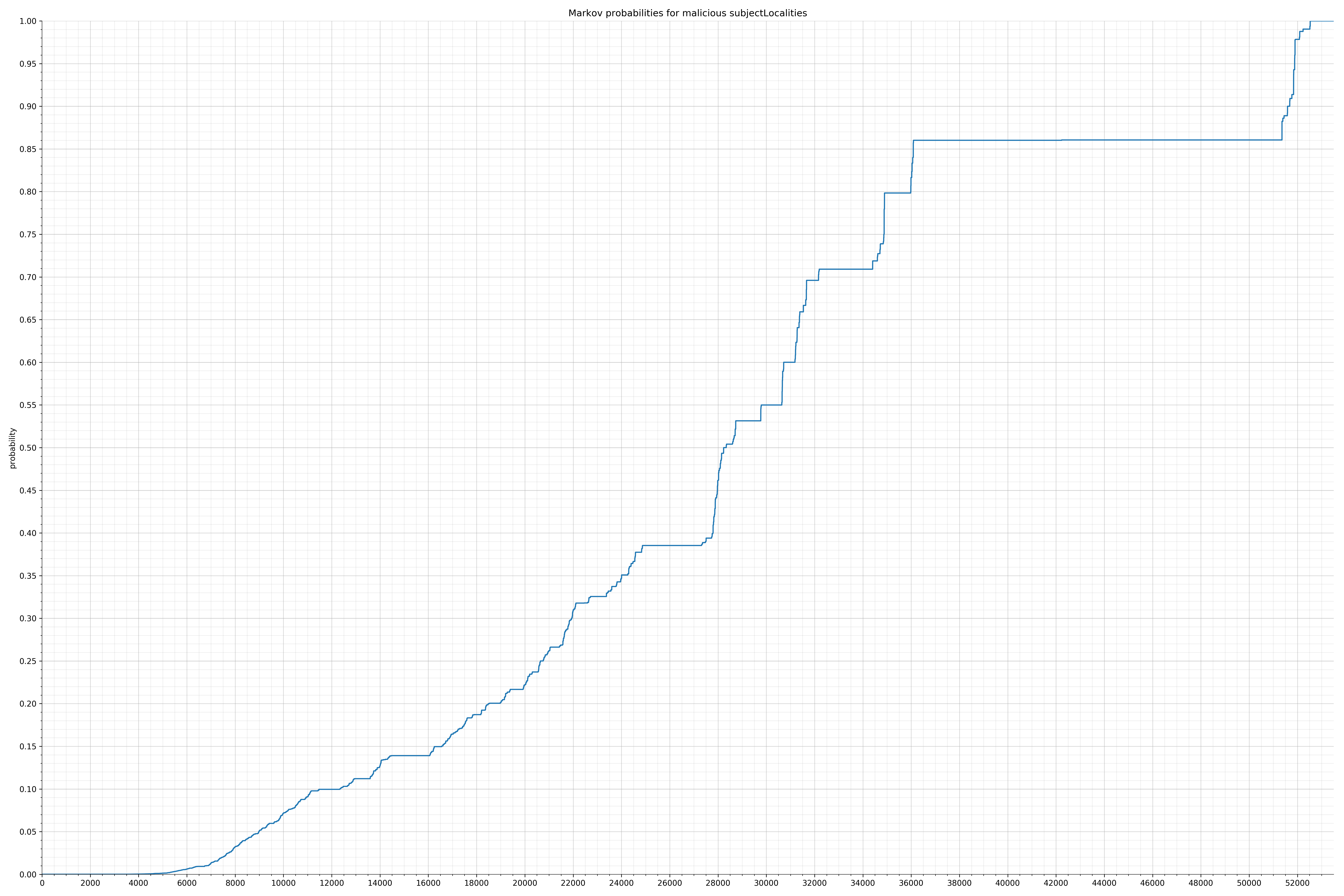
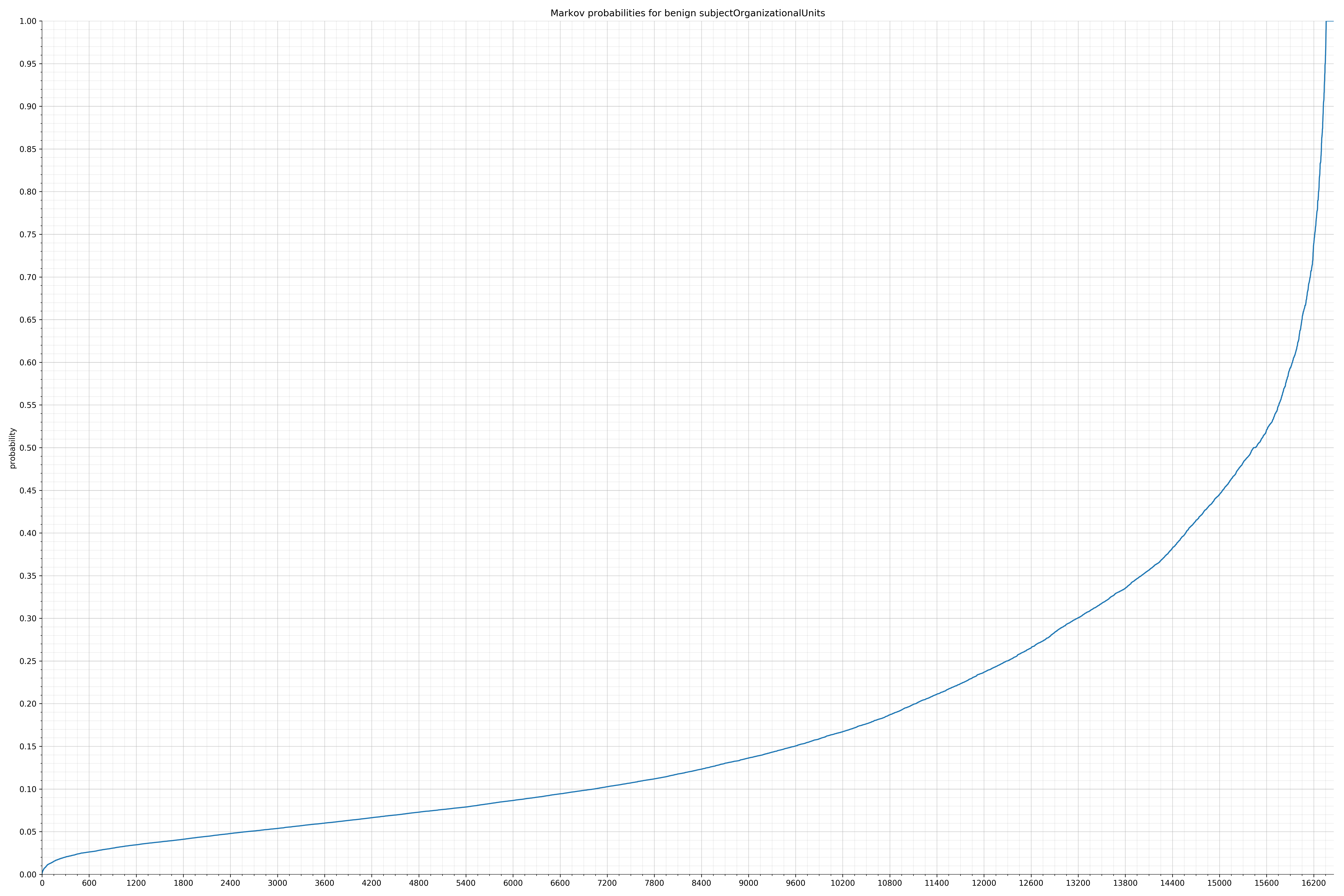
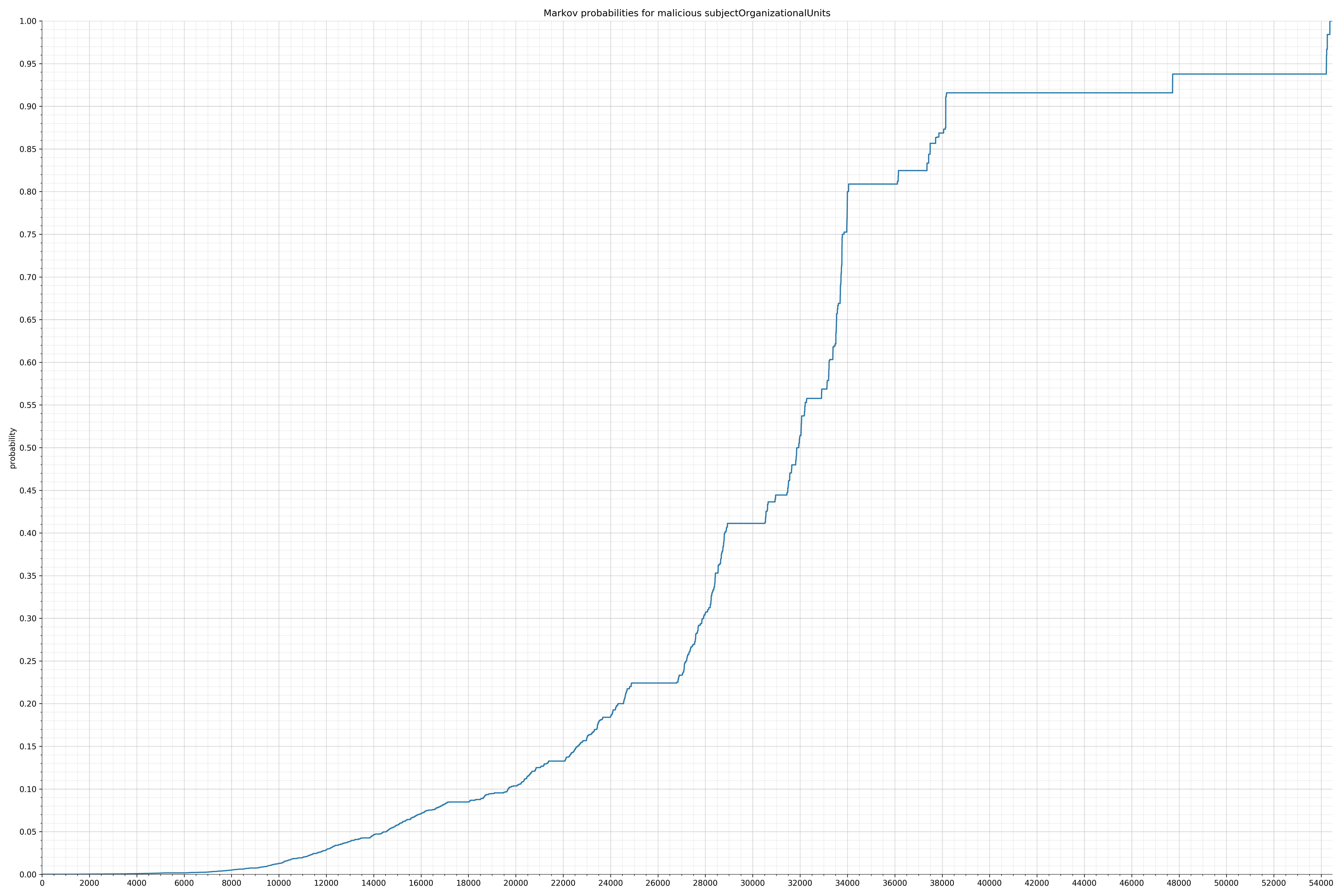
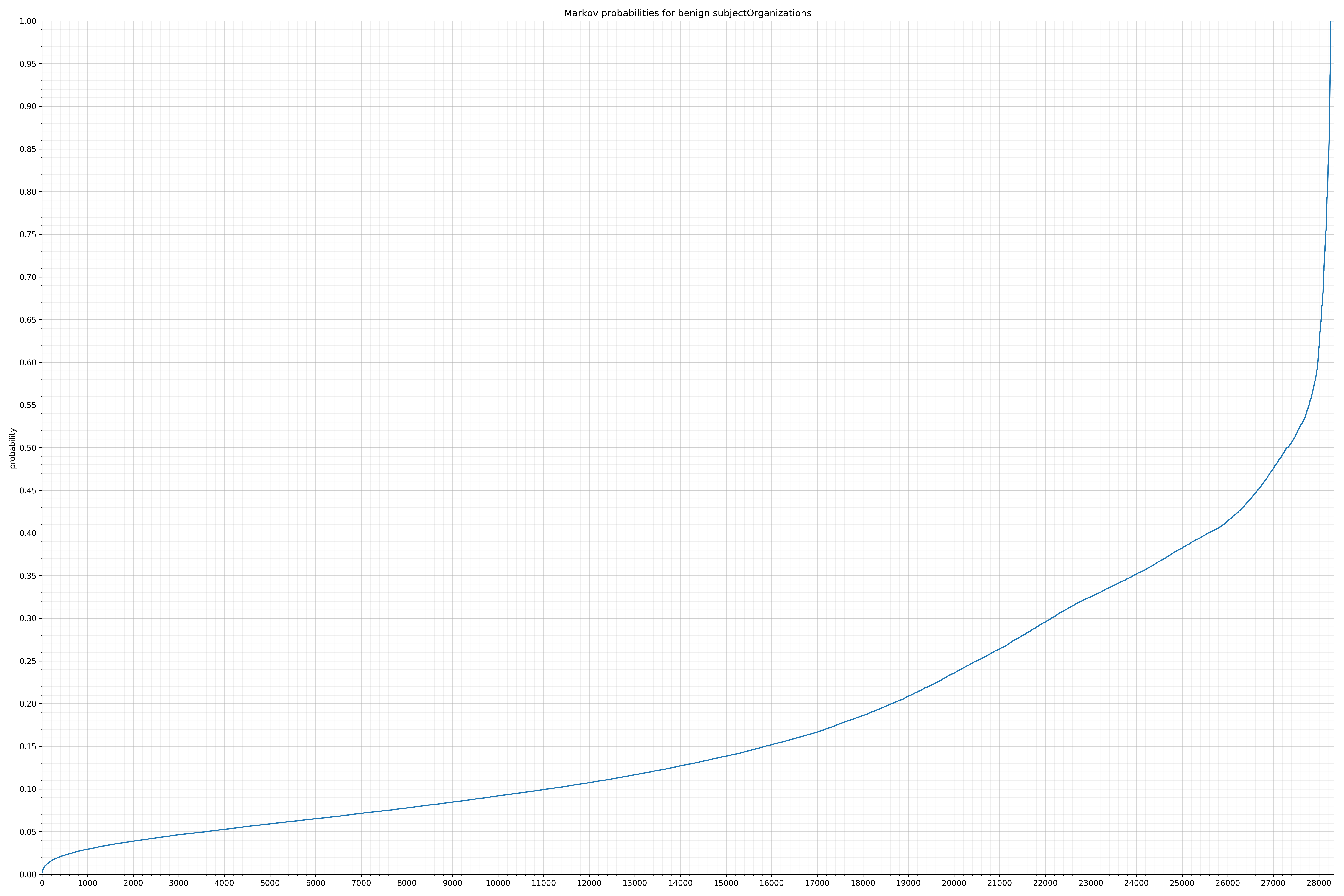
String categories and the probability distributions are listed below.
From the Android manifest:
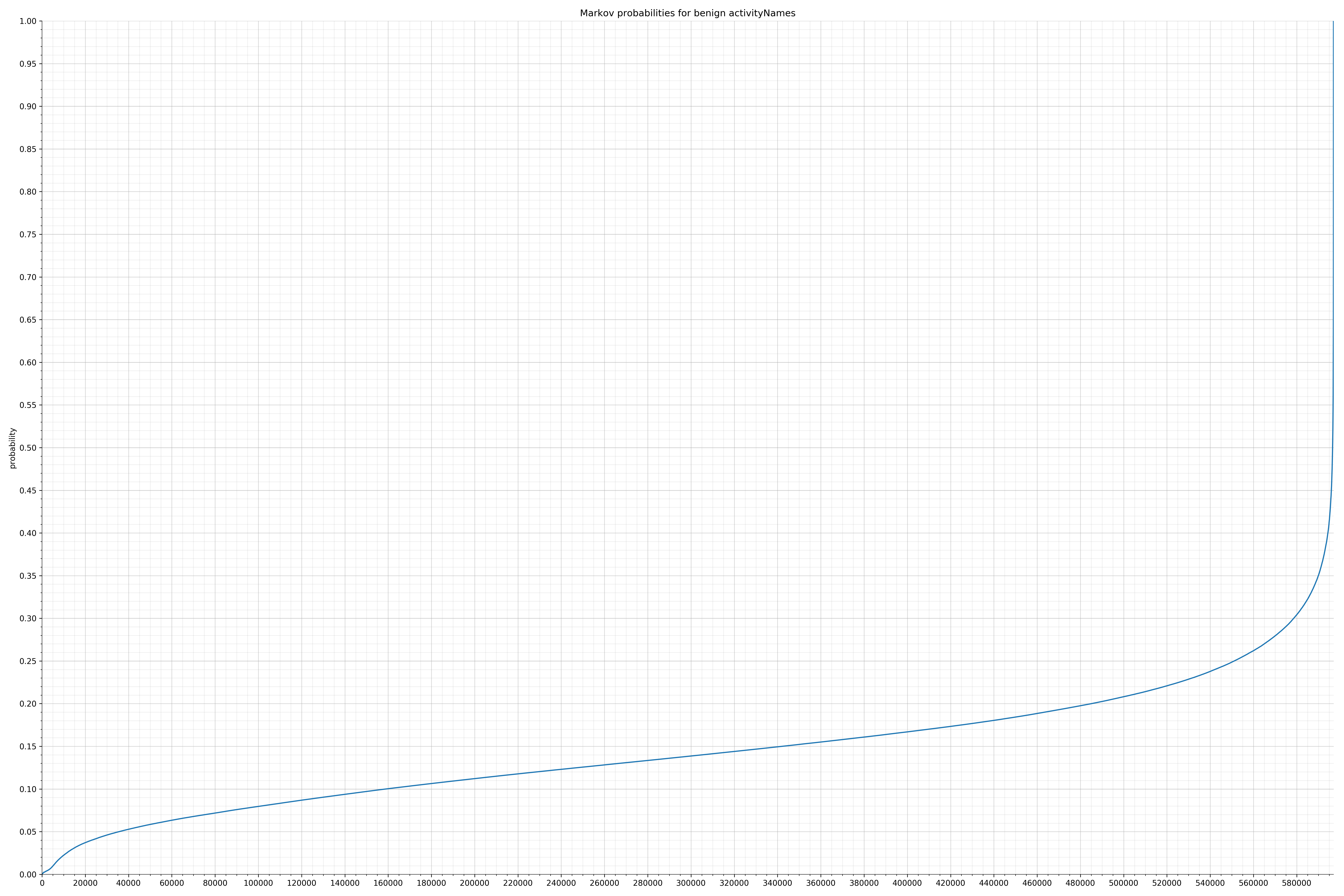
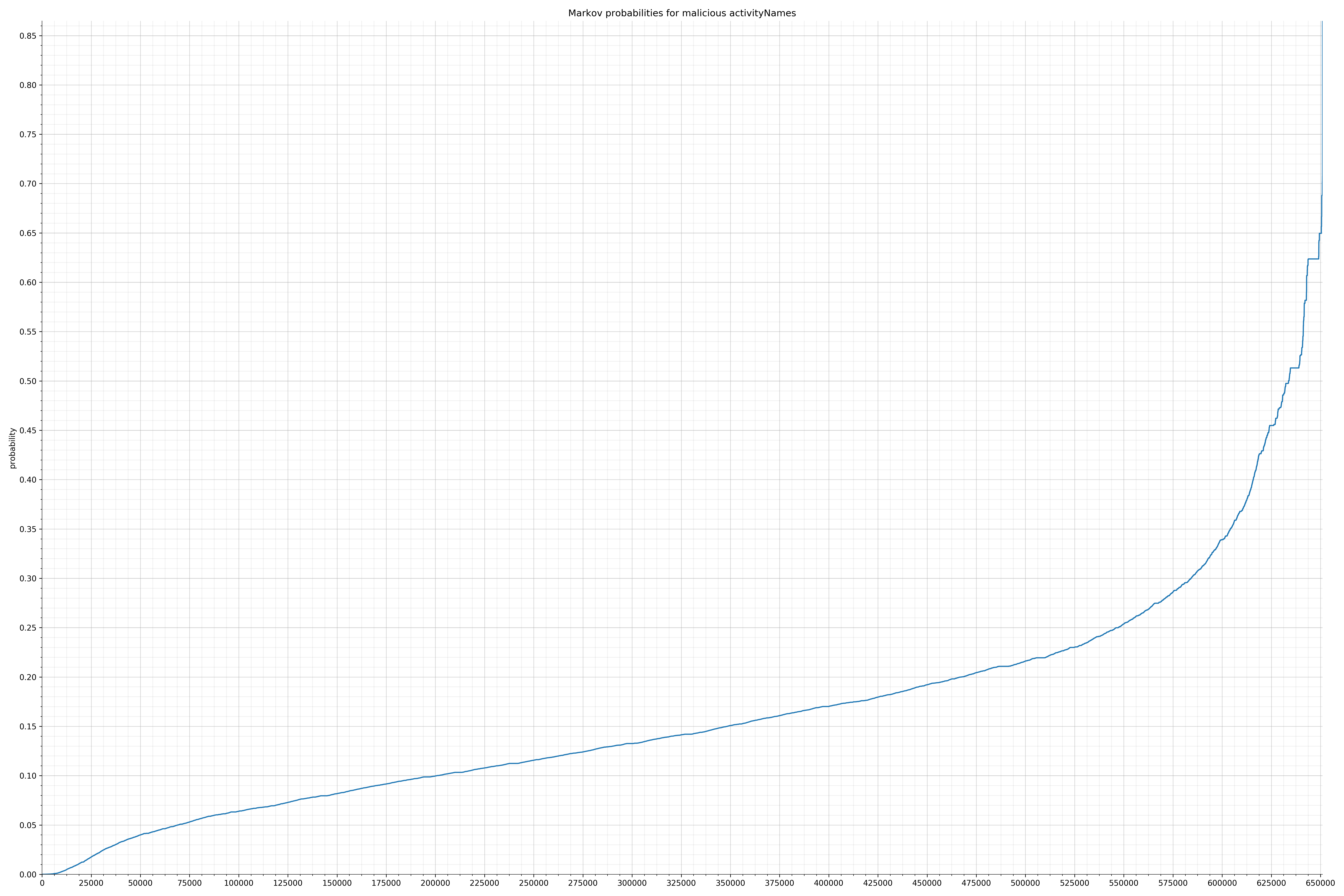
- activityNames - benign / malicious
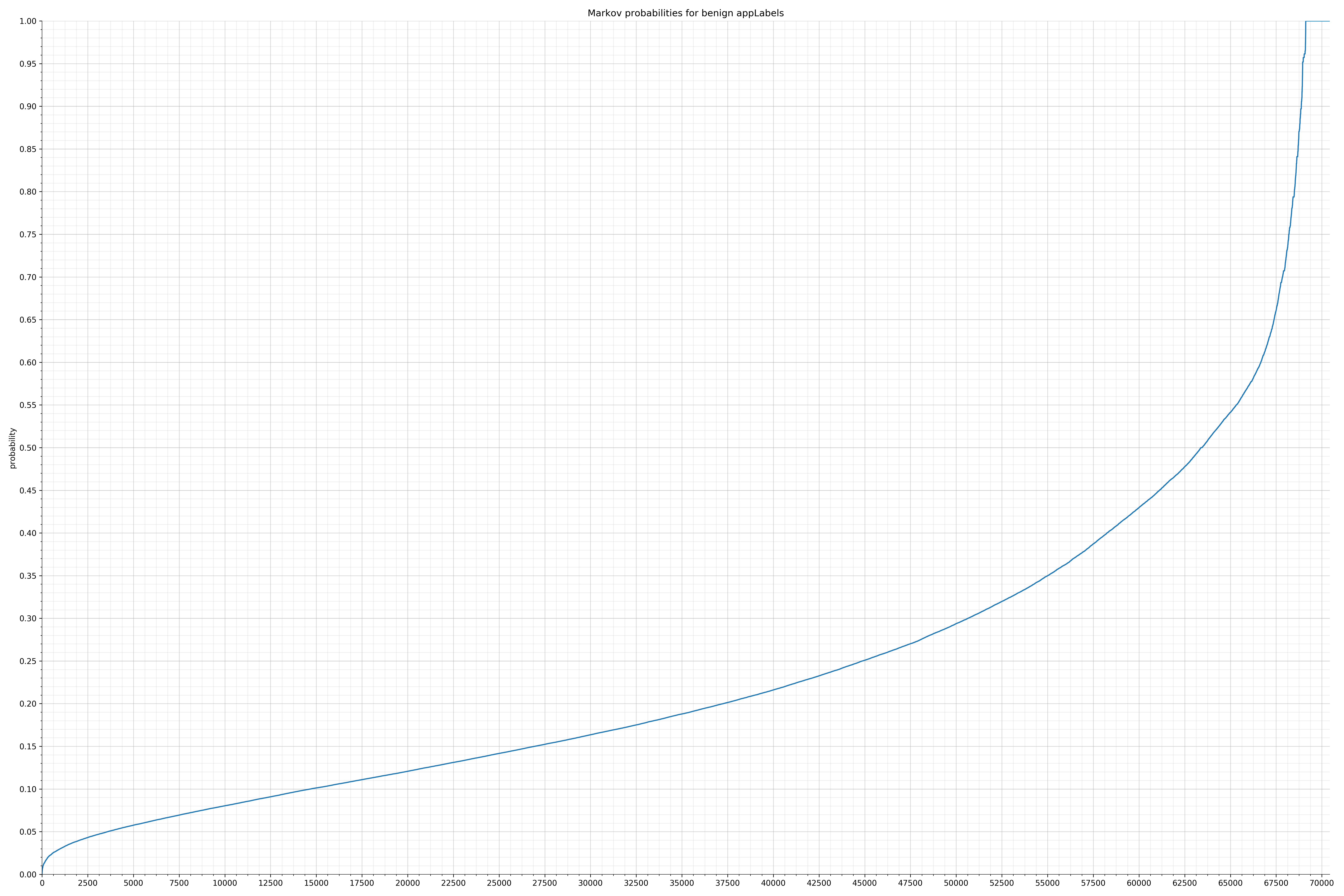
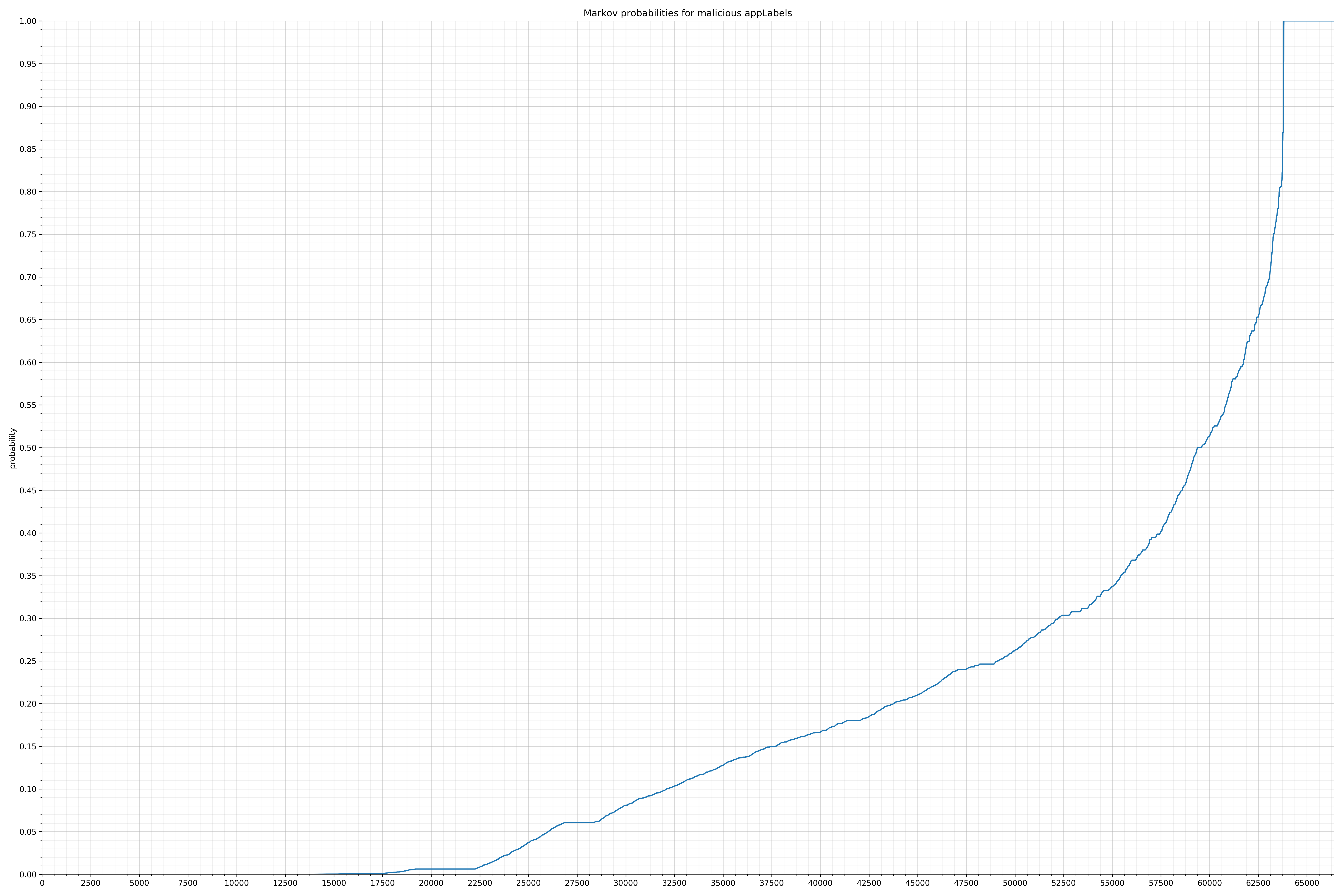
- appLabels - benign / malicious
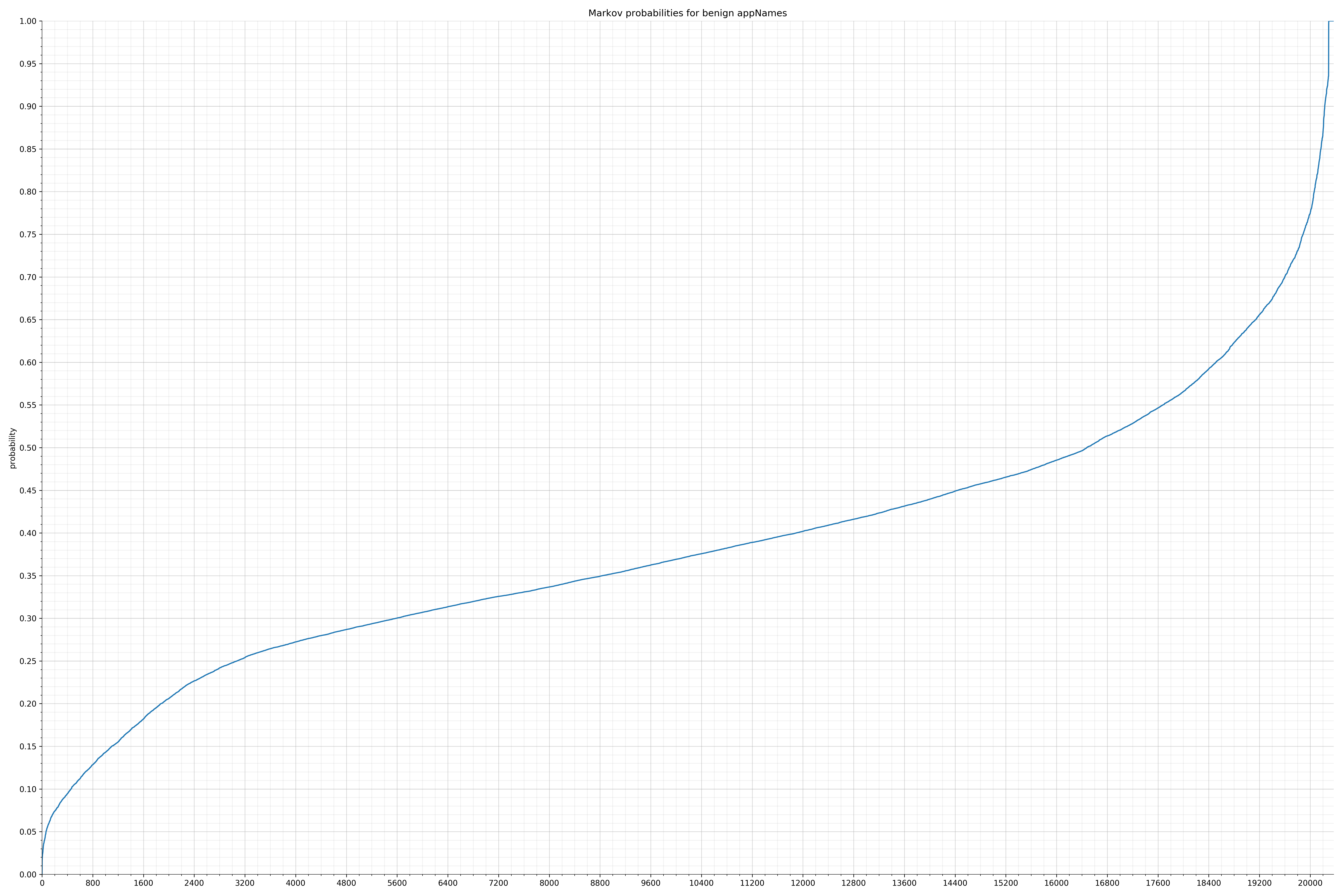
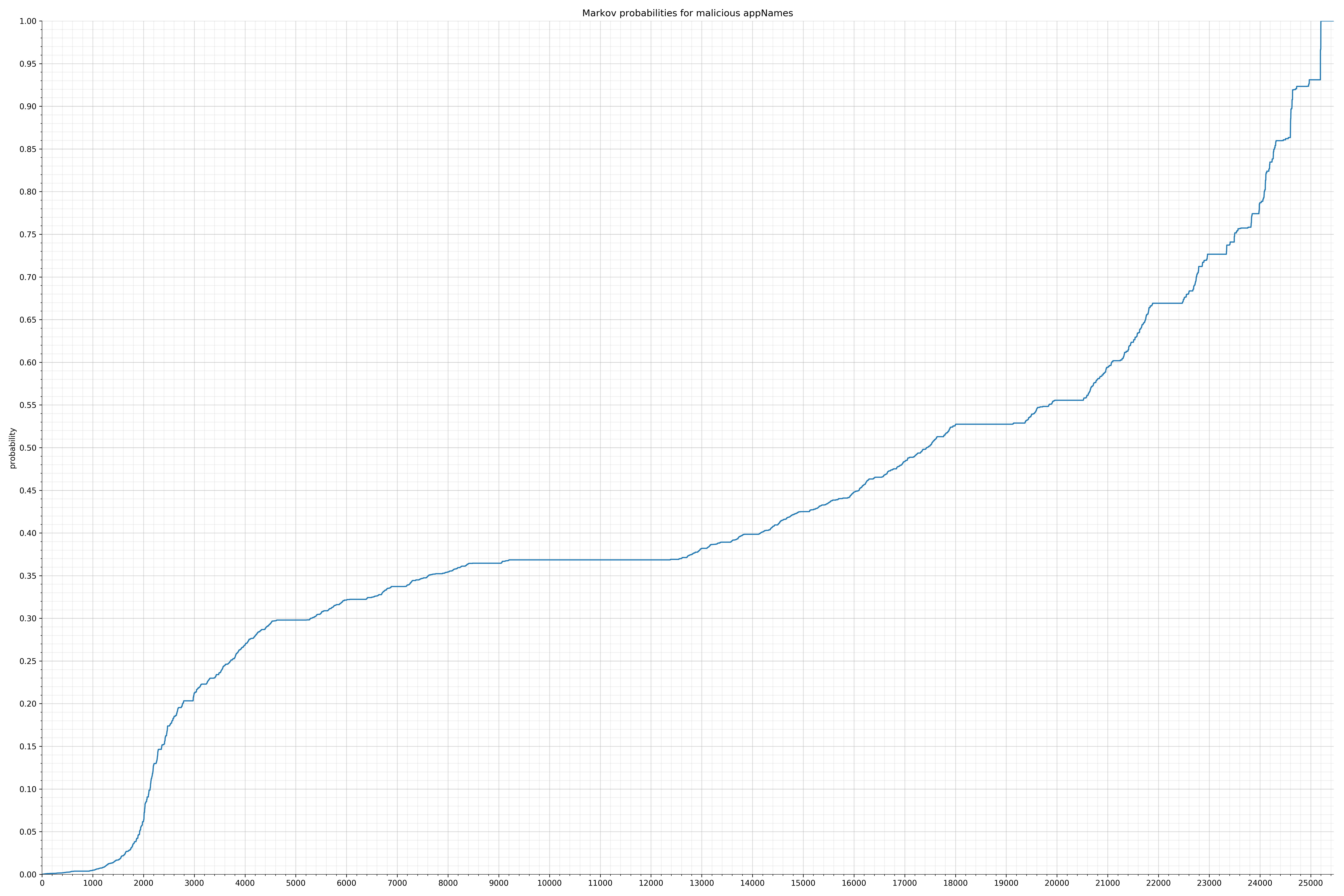
- appNames - benign / malicious
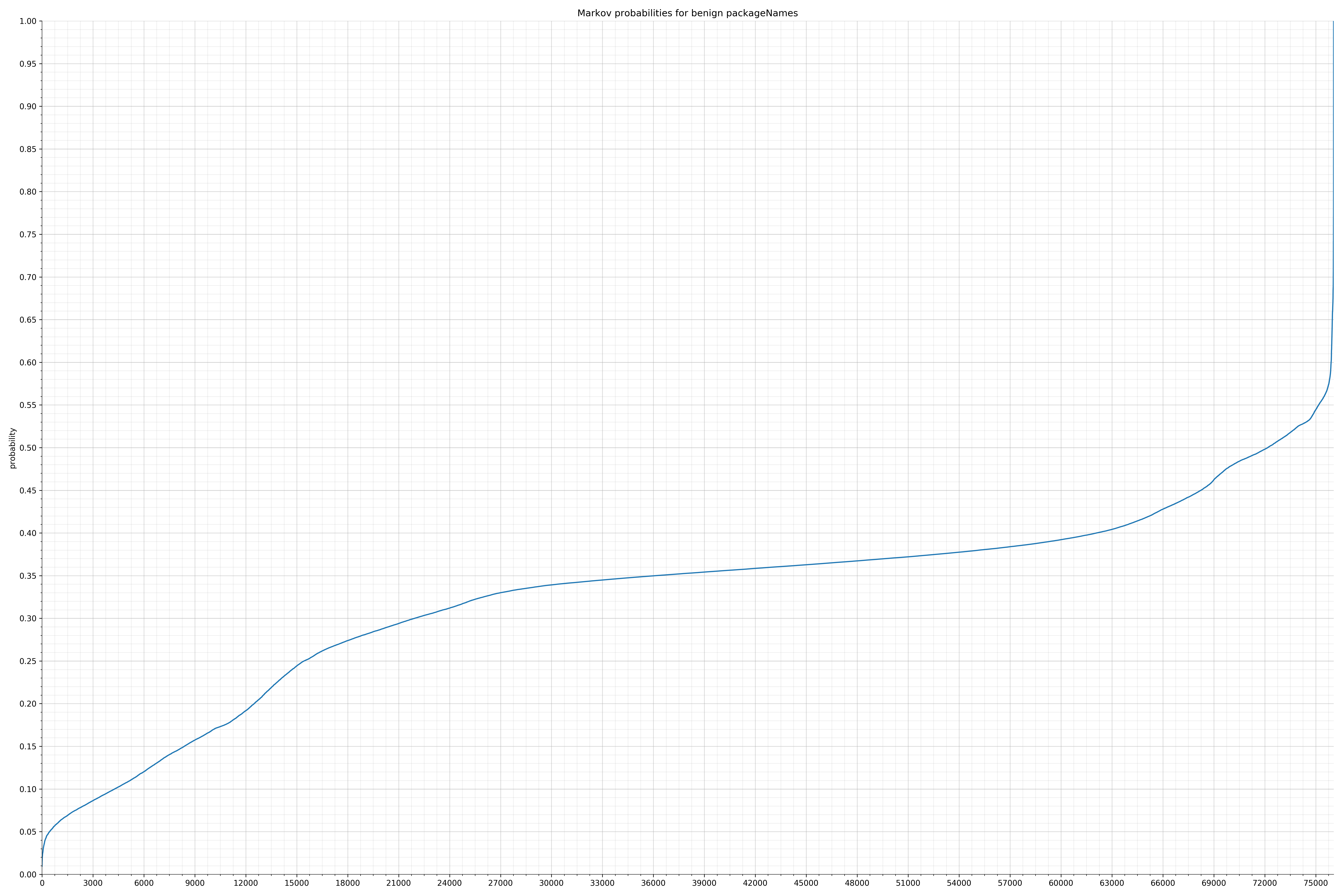
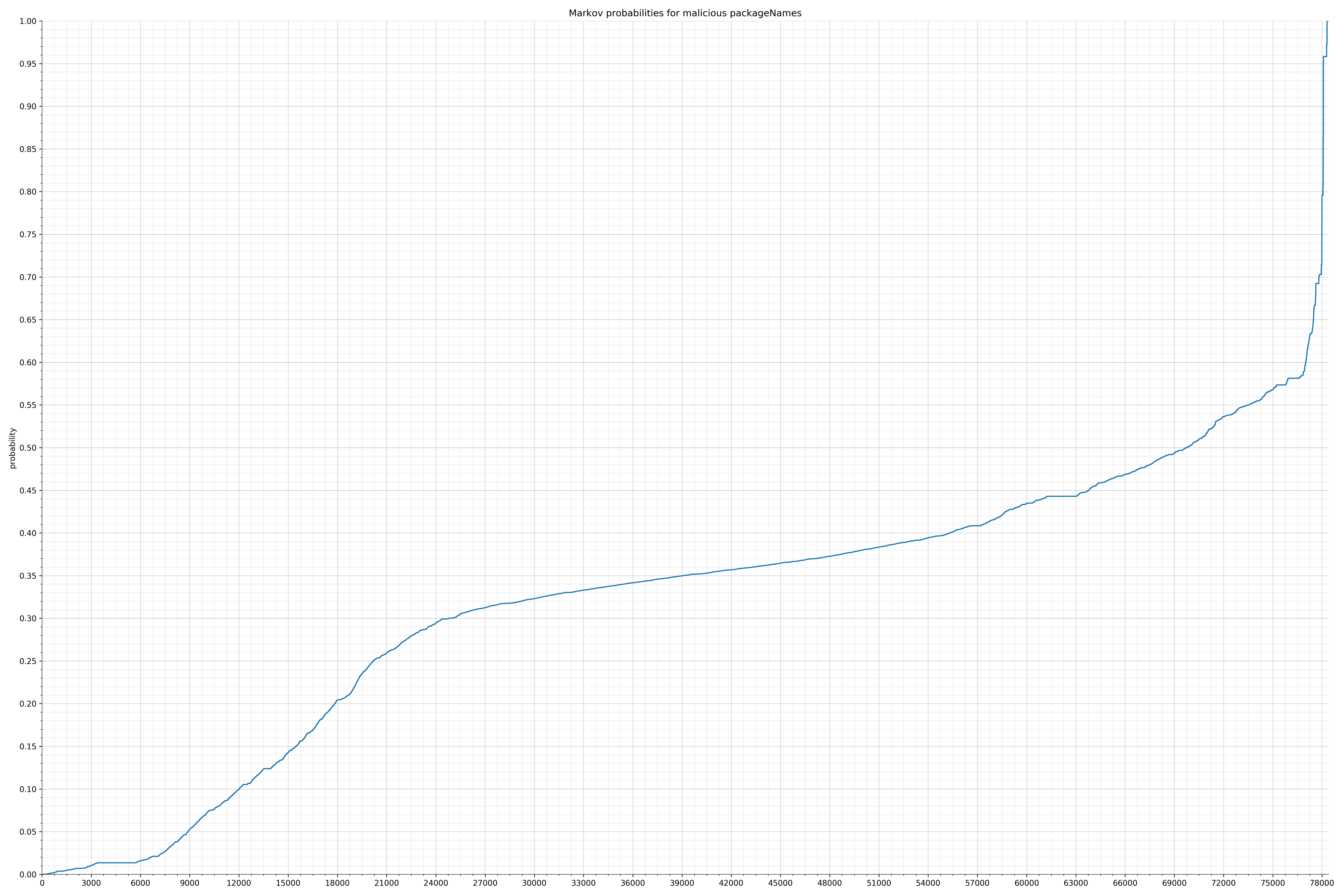
- packageNames - benign / malicious
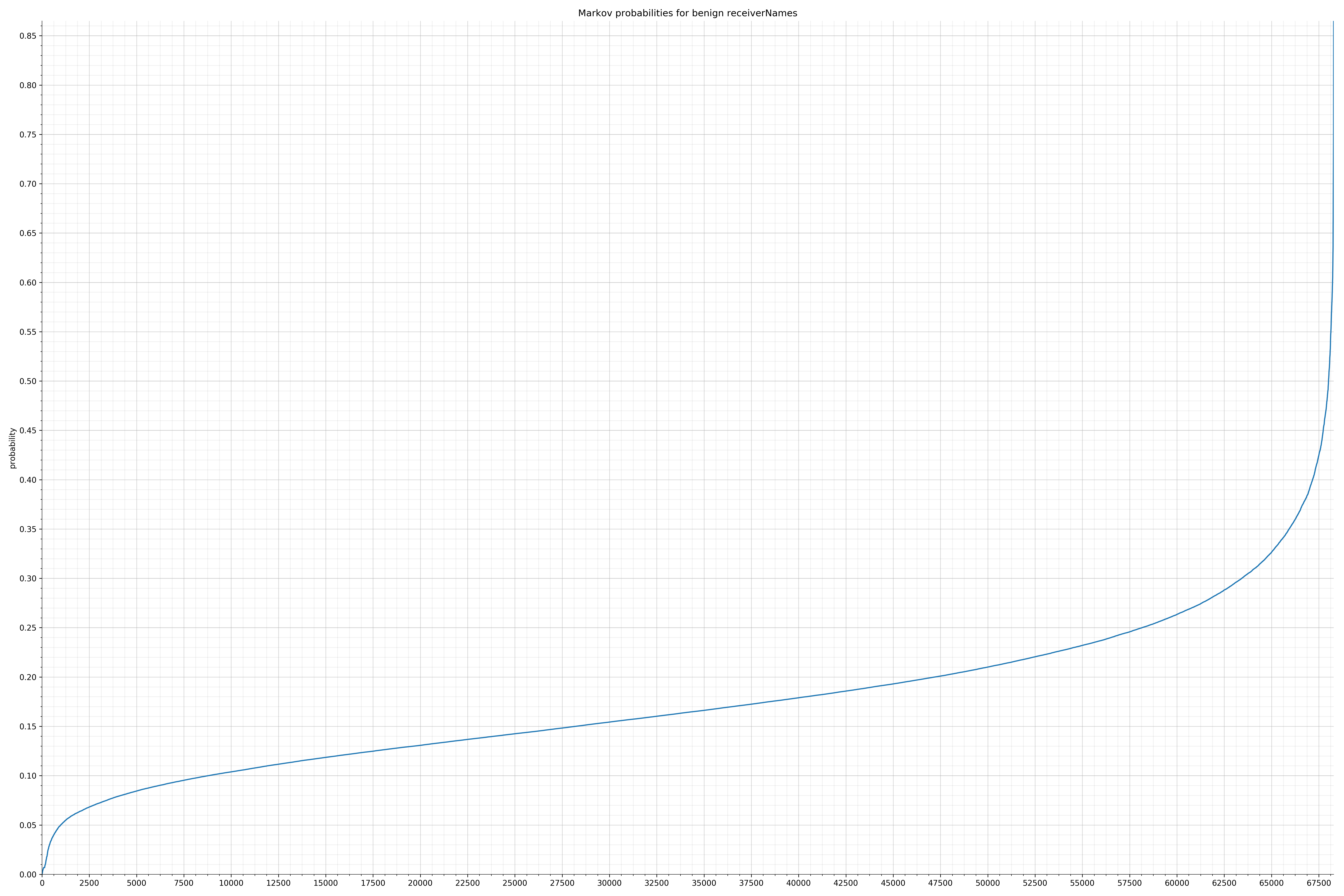
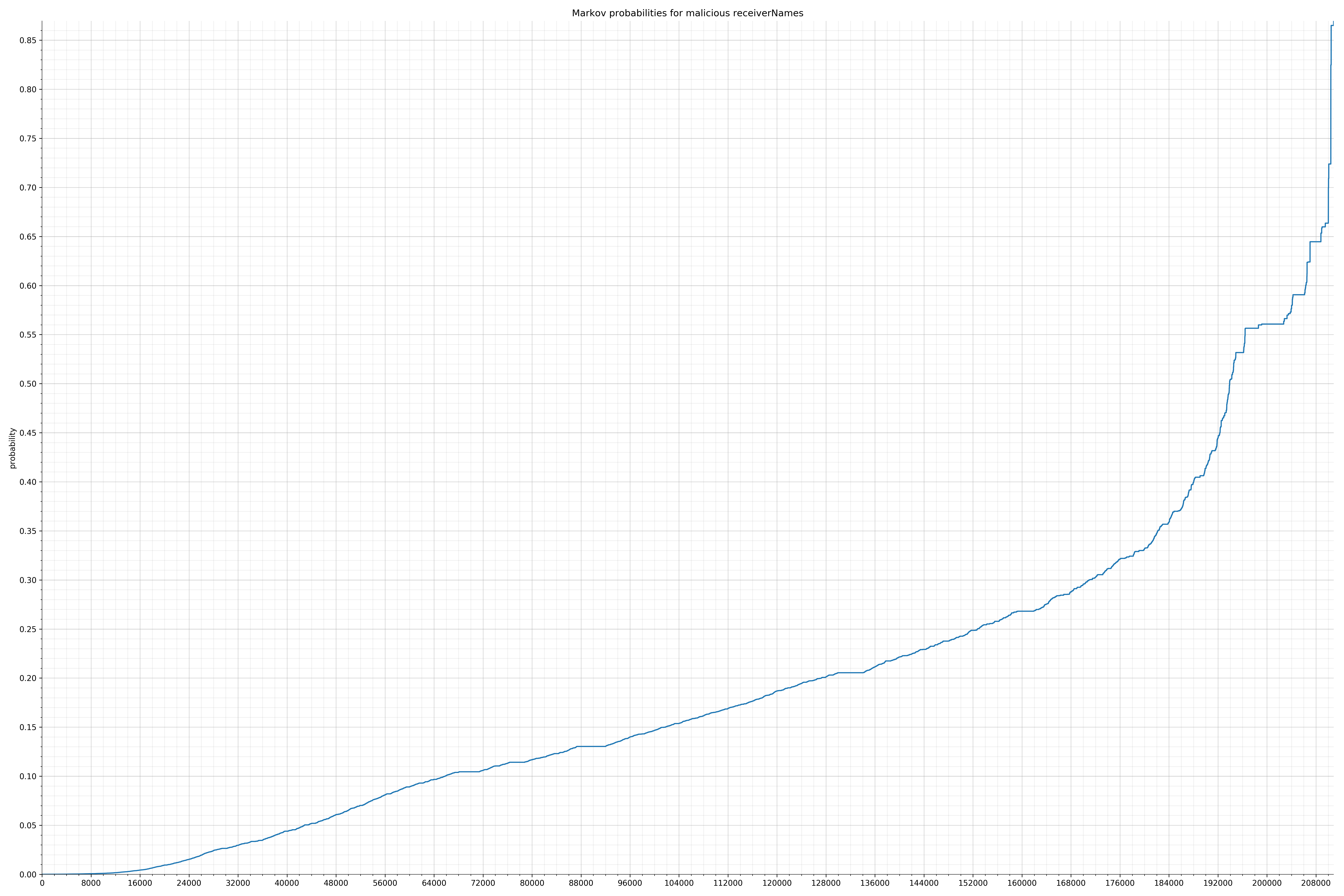
- receiverNames - benign / malicious
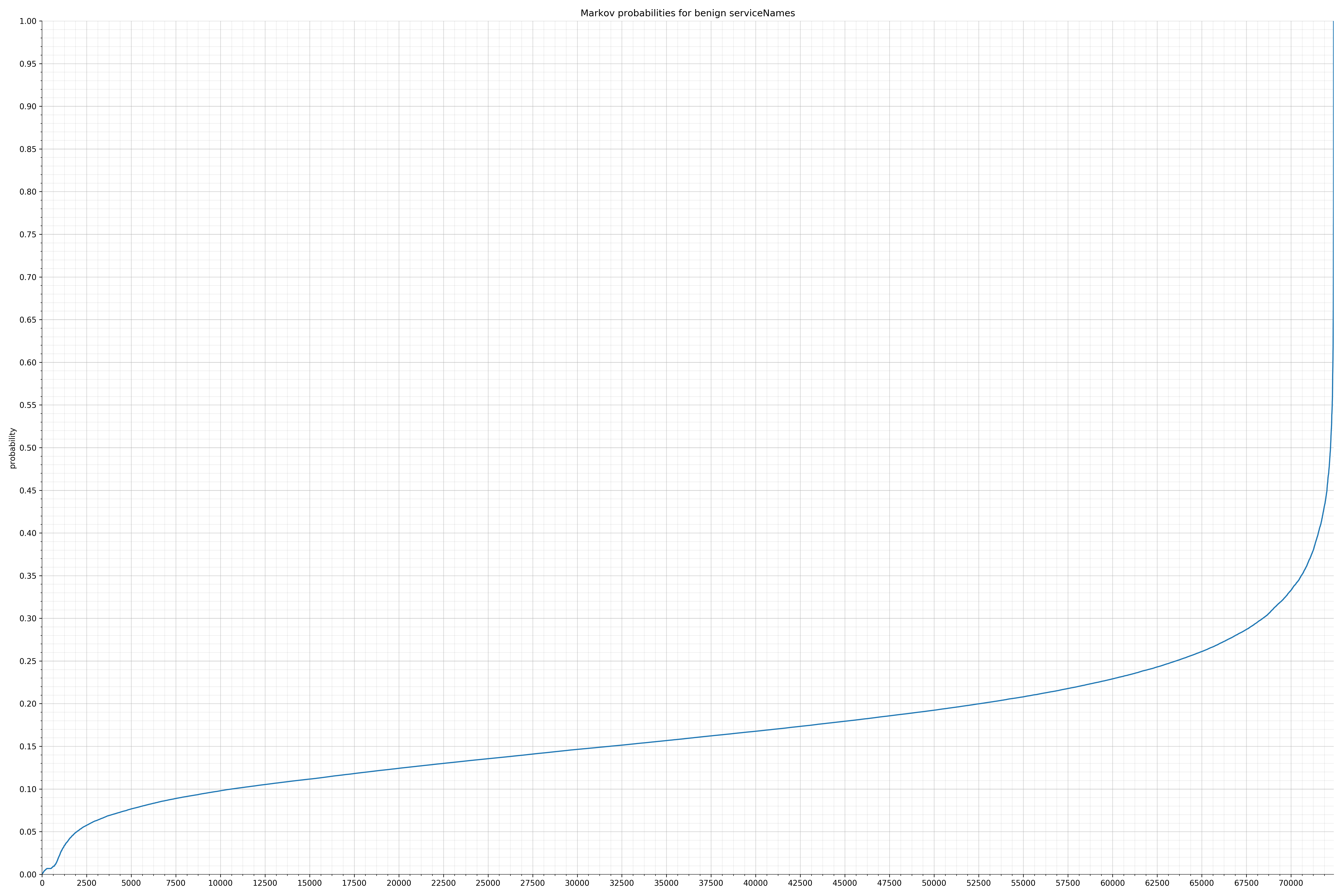
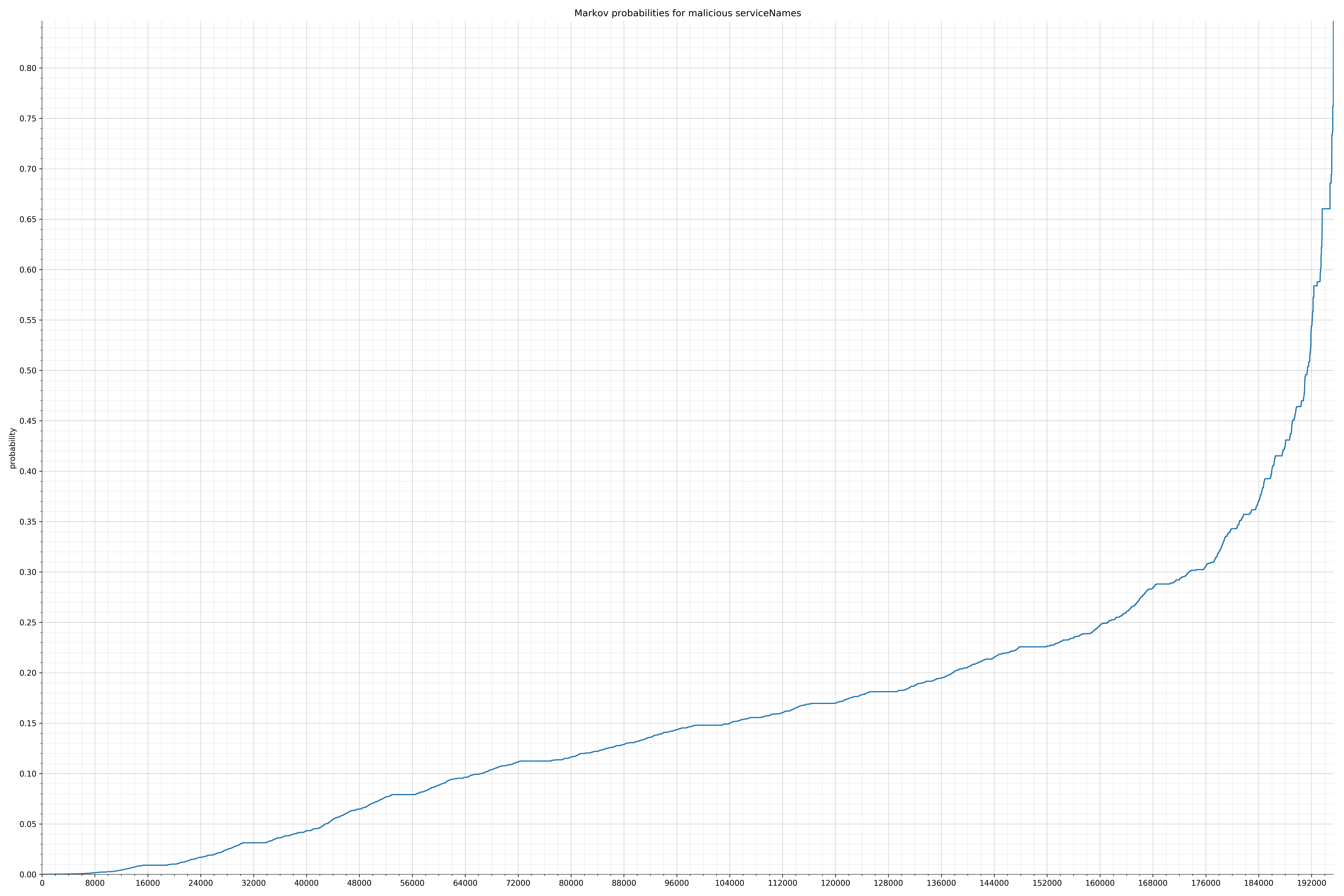
- serviceNames - benign / malicious
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
From the Dalvik executable code:
- classNames - benign / malicious
- fieldNames - benign / malicious
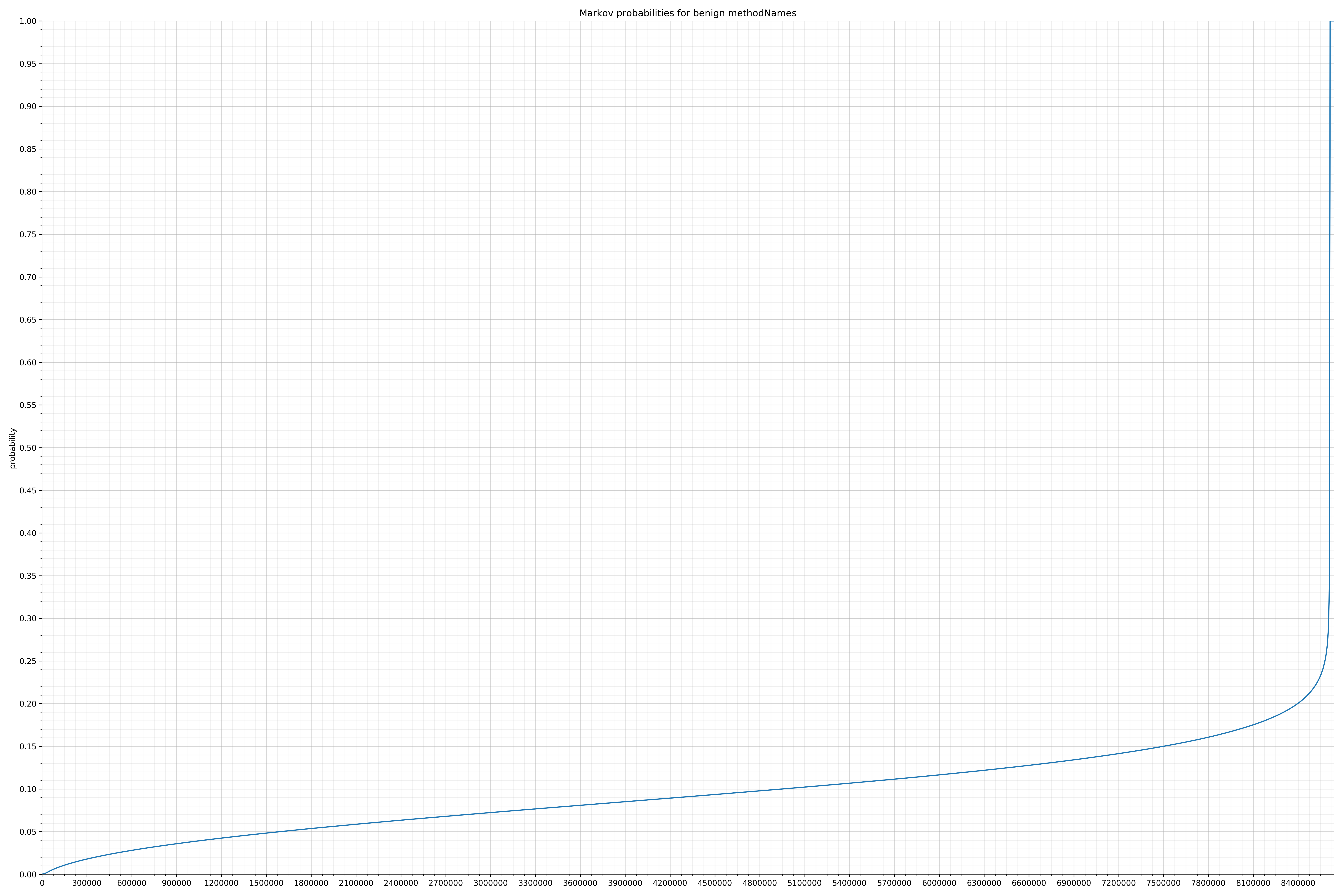
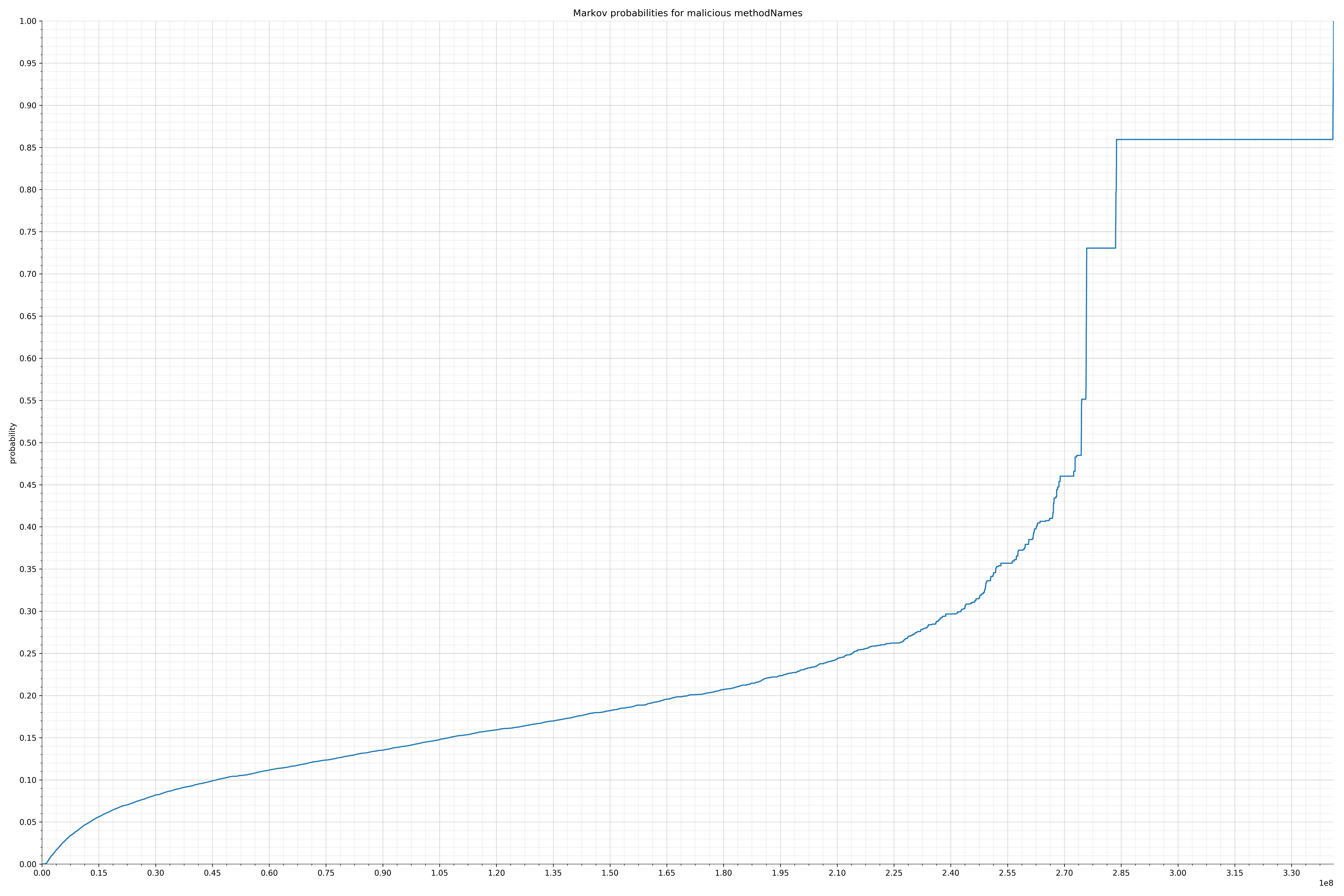
- methodNames - benign / malicious
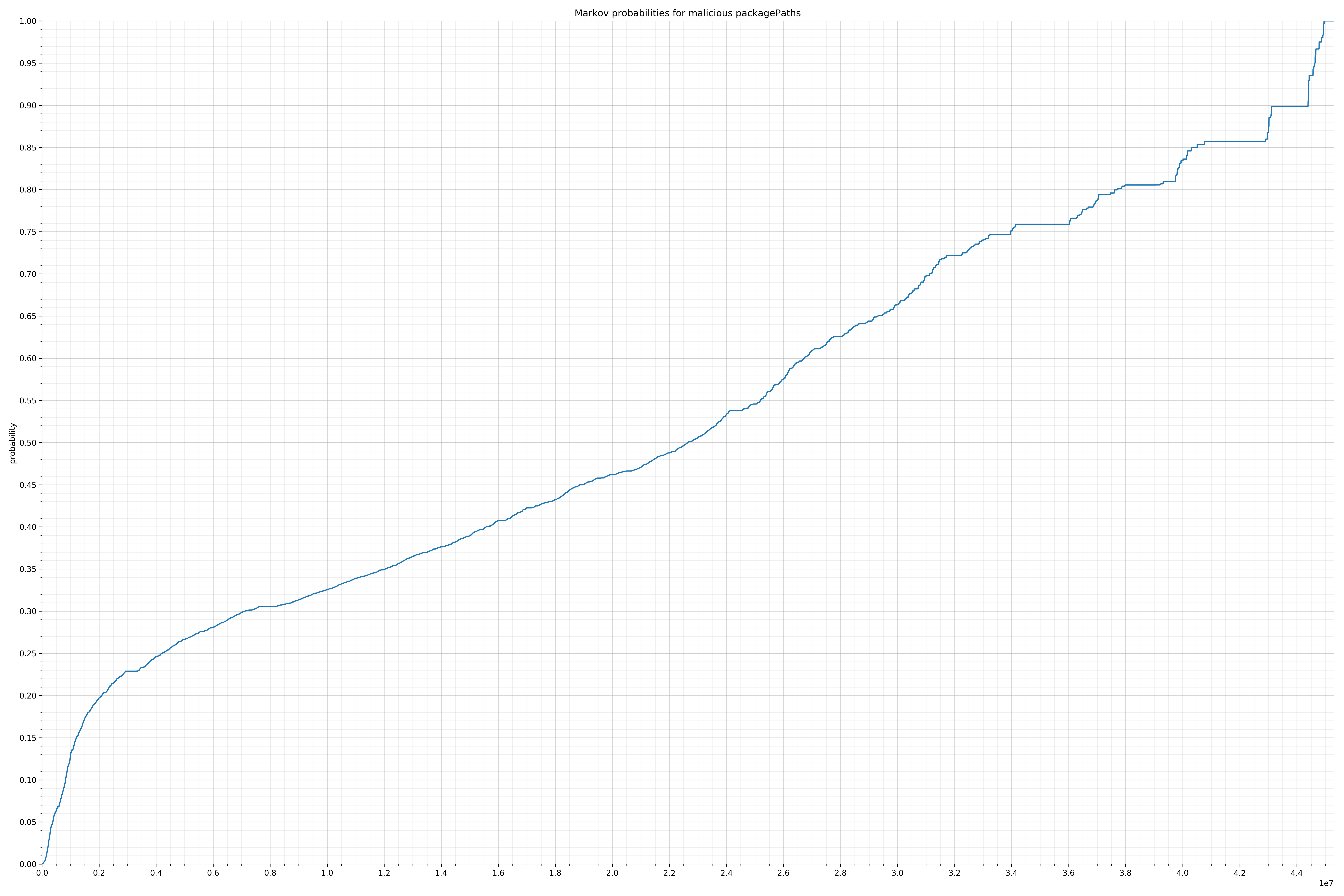
- packagePaths - benign / malicious
- stringLiterals - benign / malicious
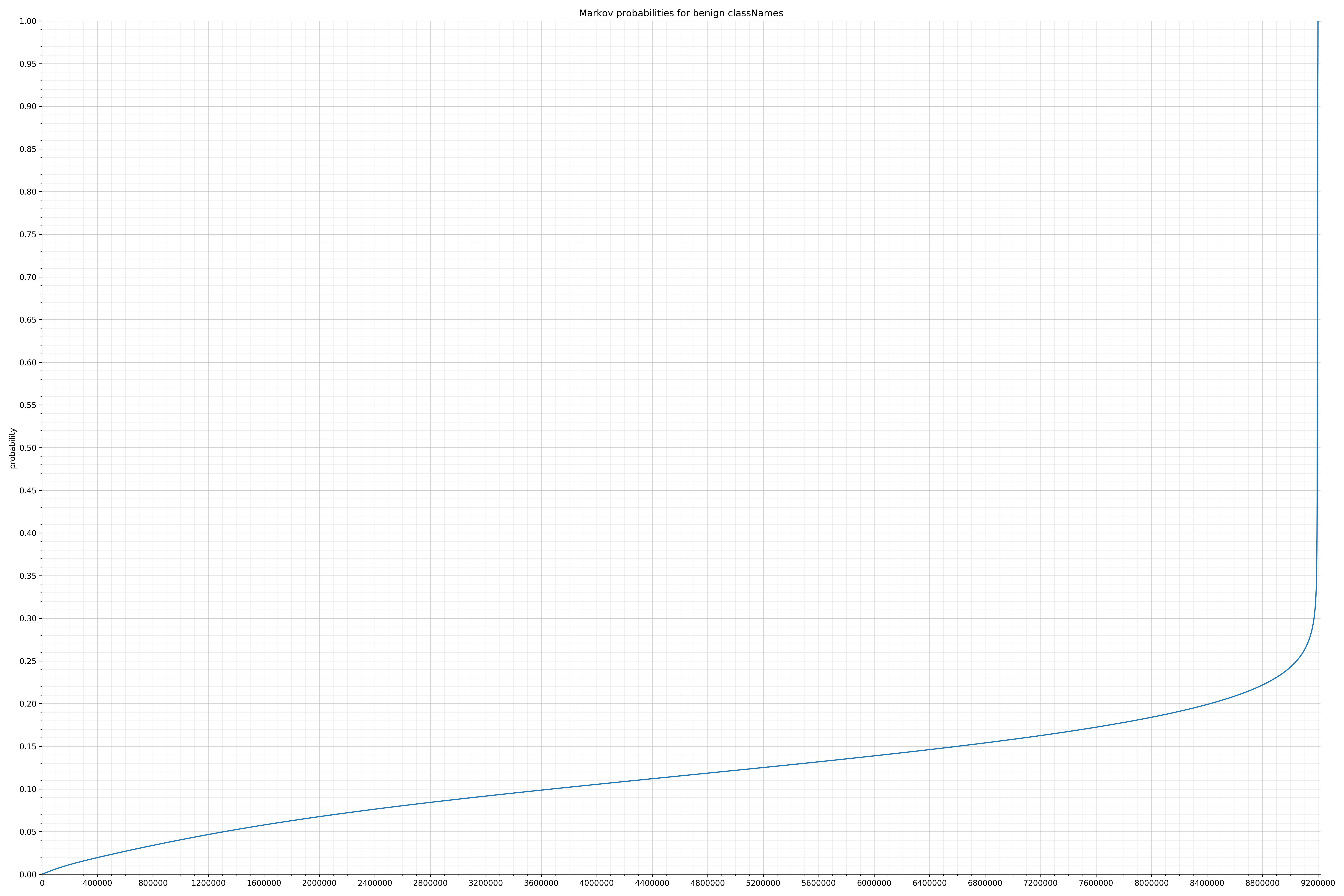{kind=link}
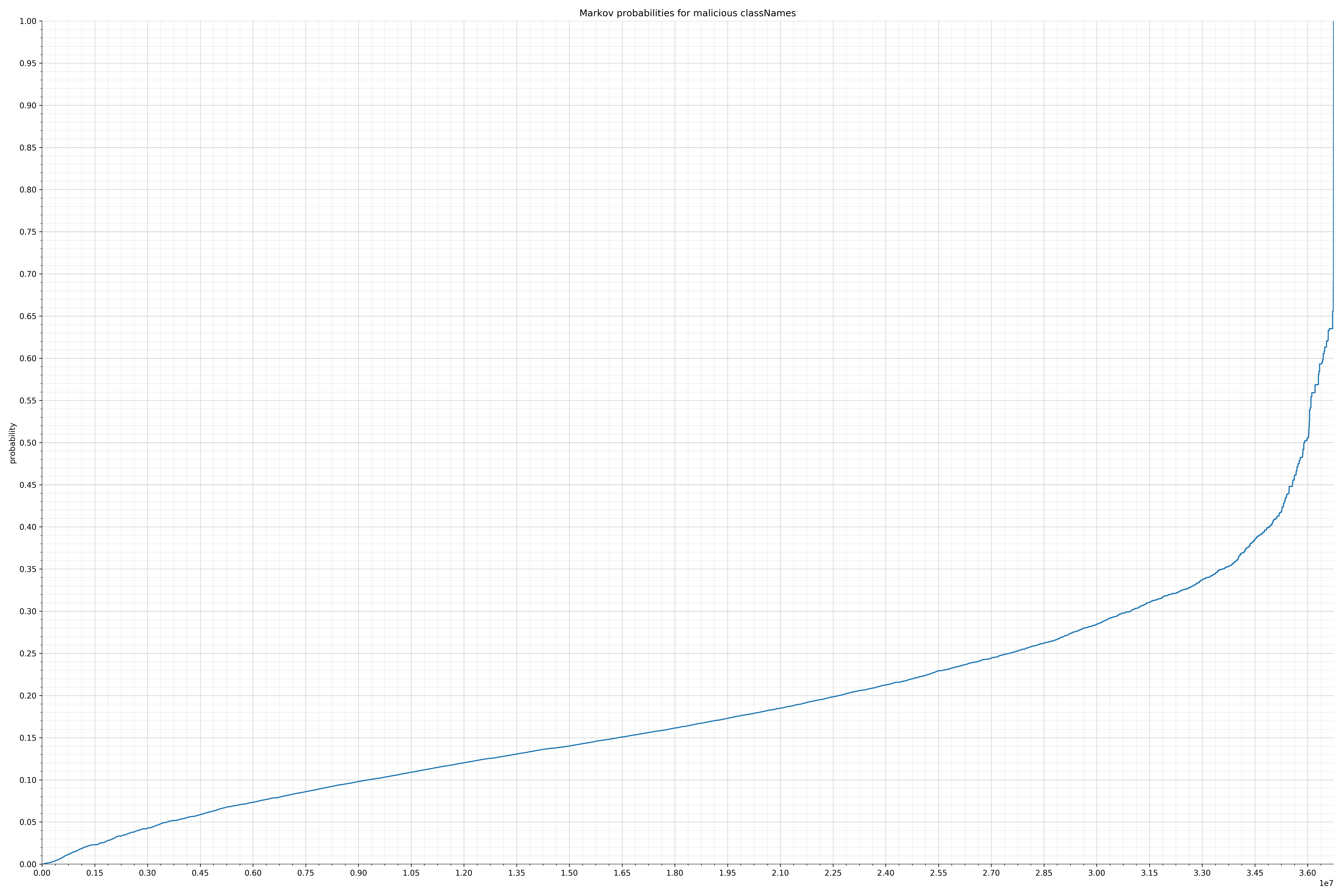{kind=link}
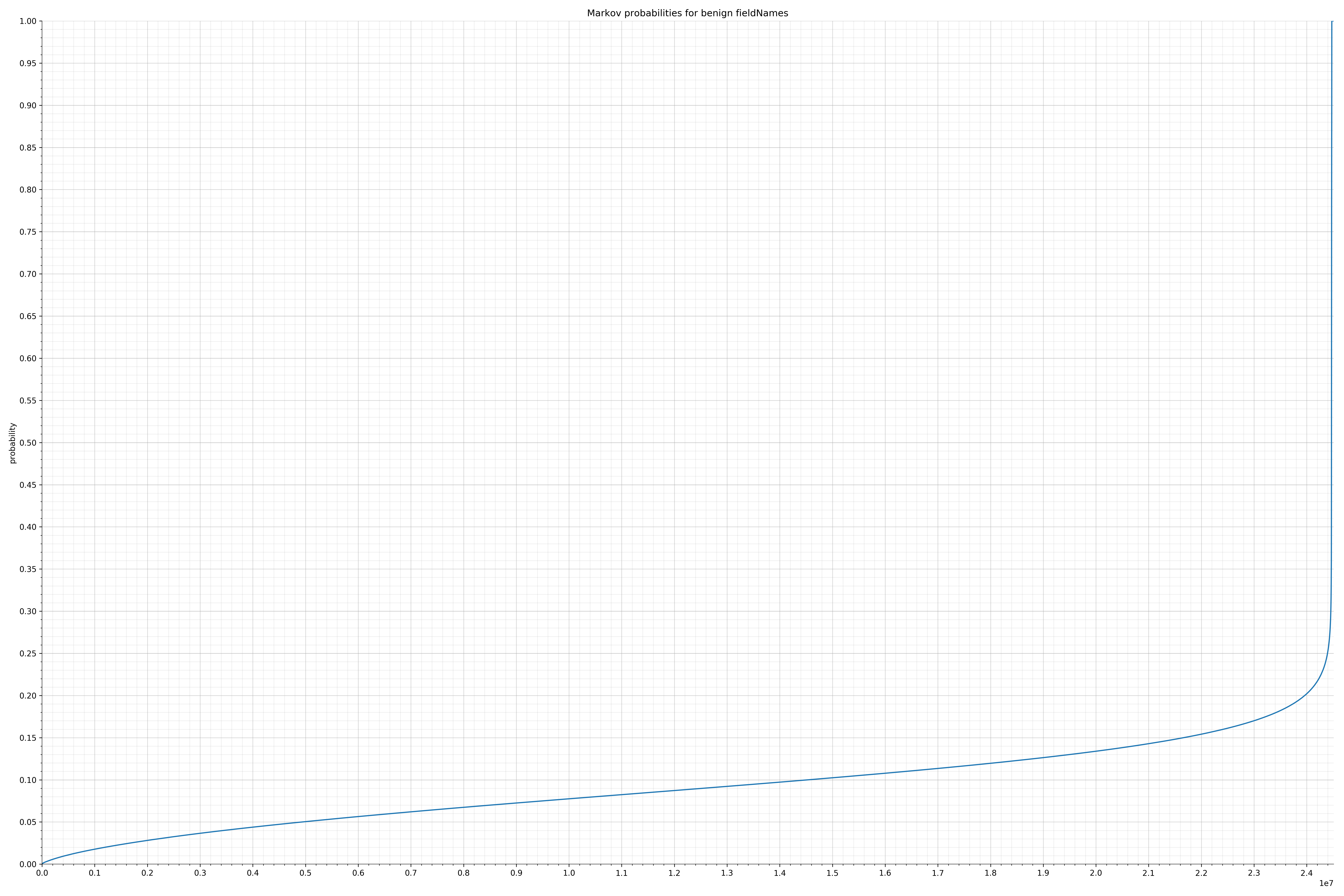{kind=link}
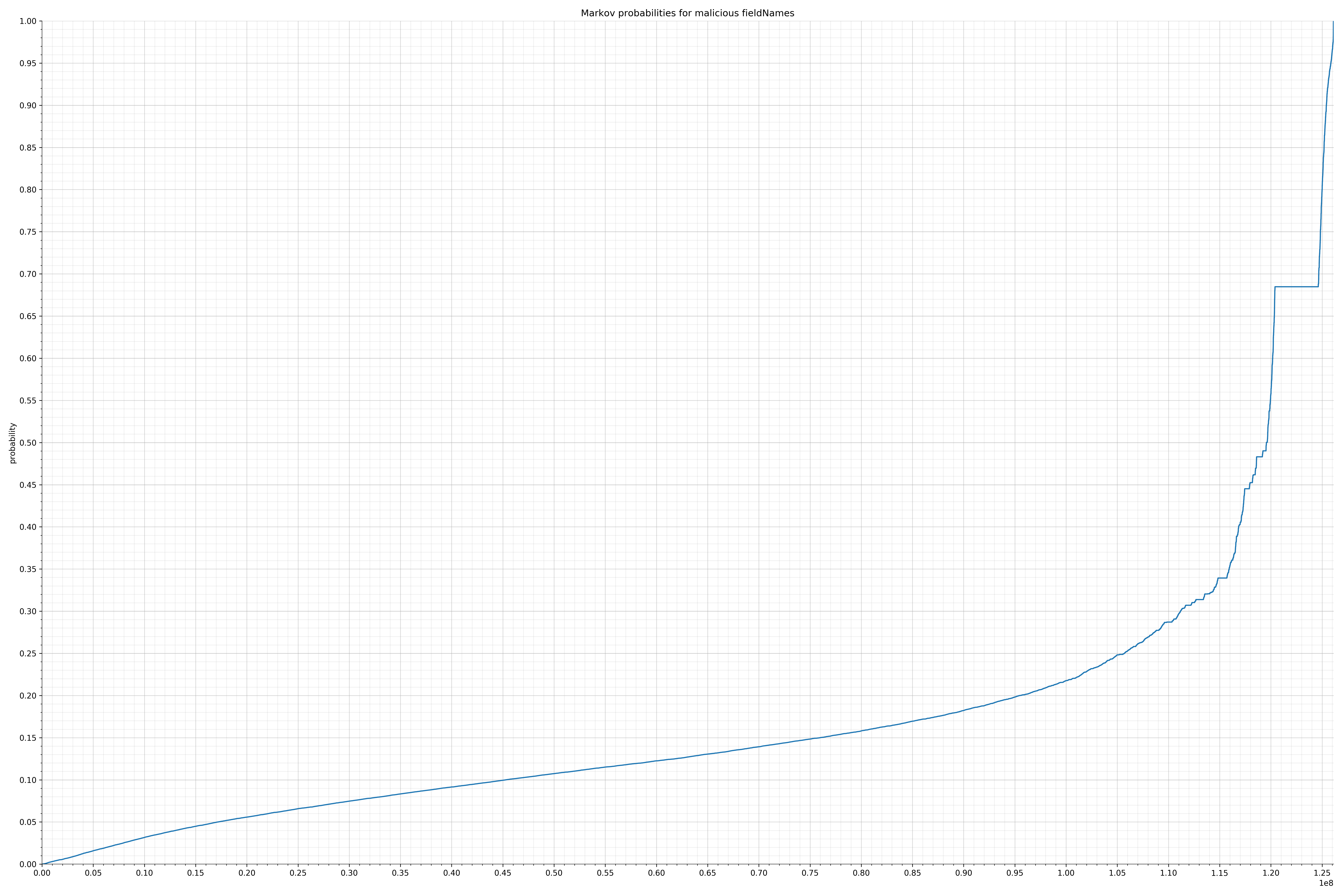{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
From the signing certificate:
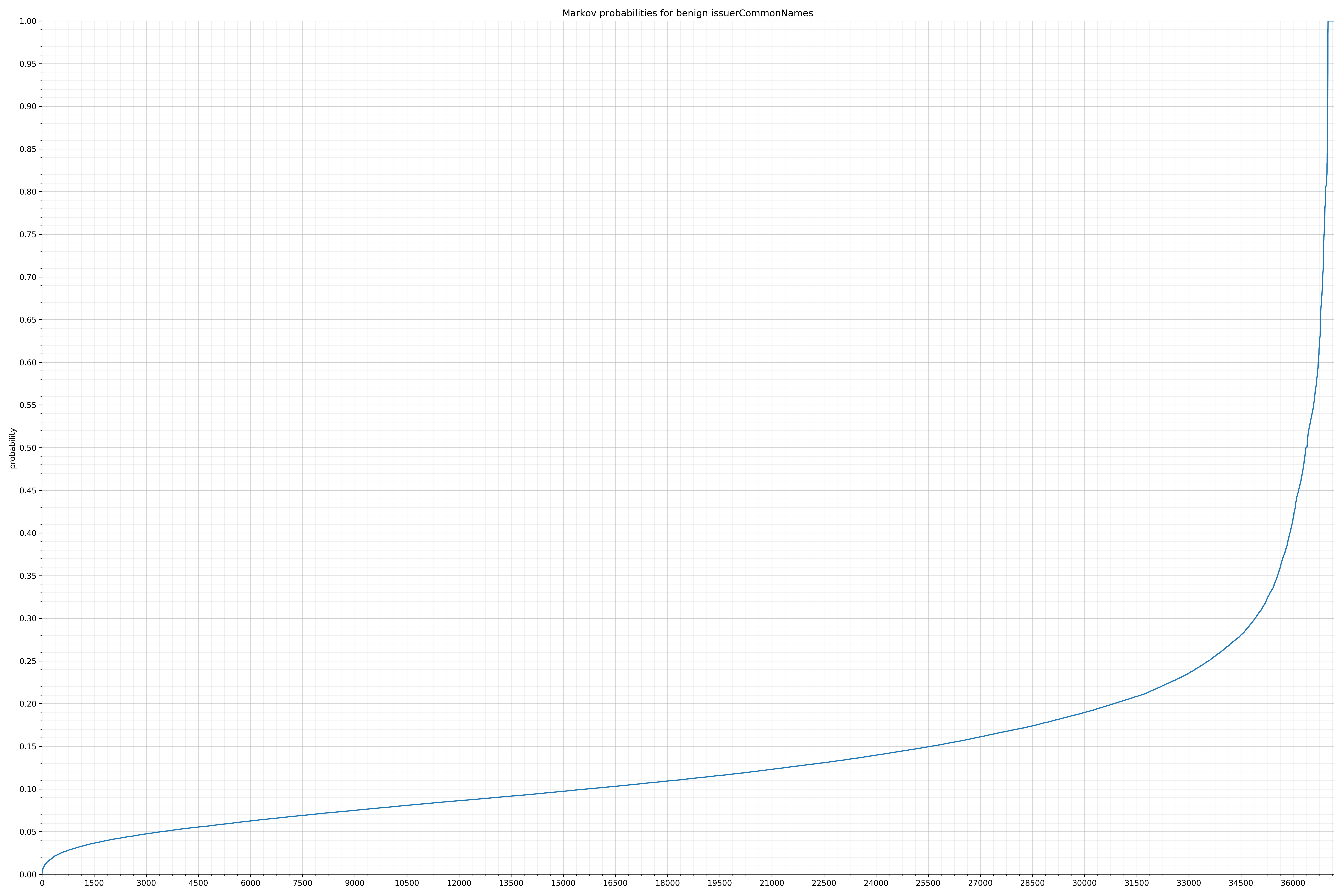
- issuerCommonNames - benign / malicious
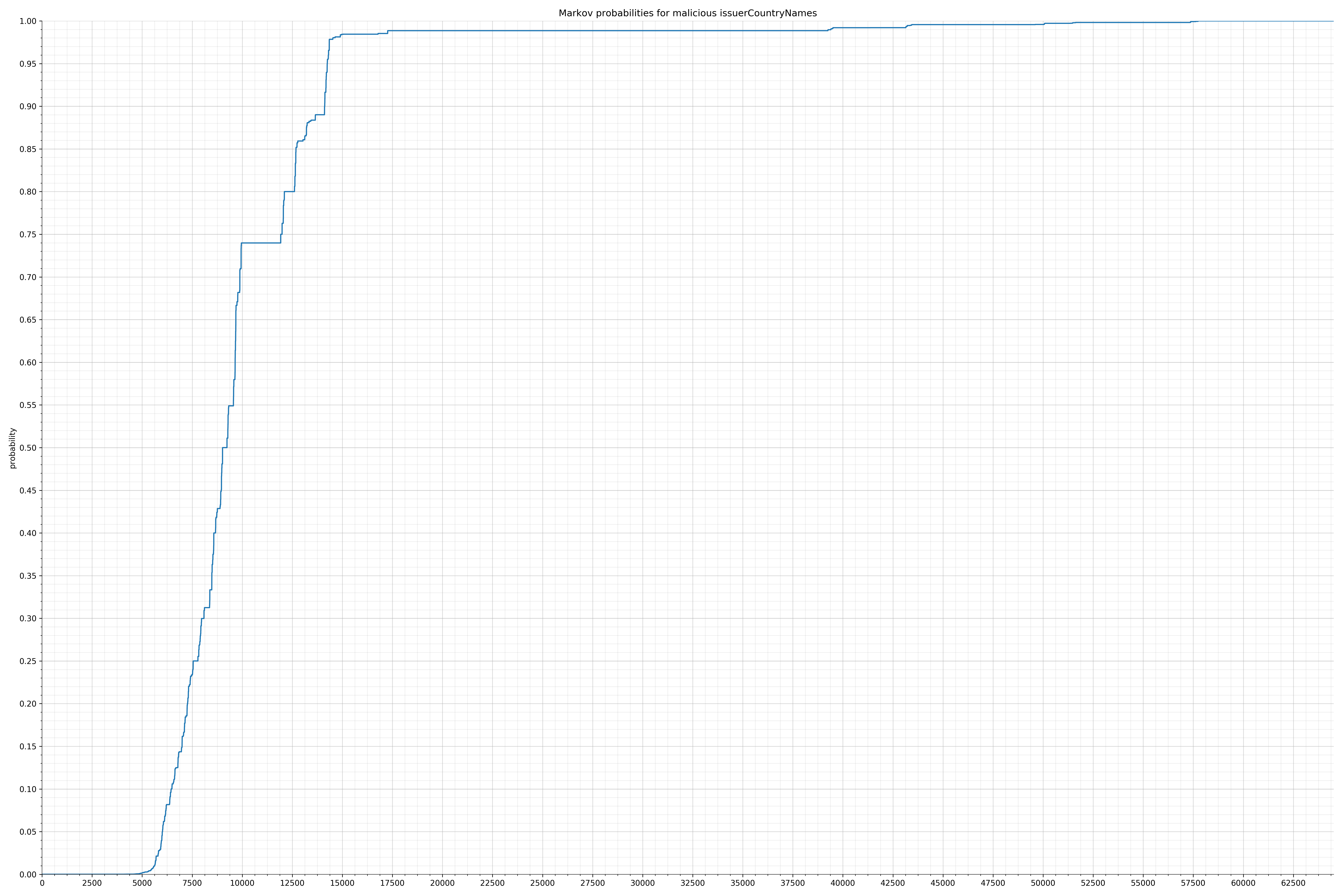
- issuerCountryNames - benign / malicious
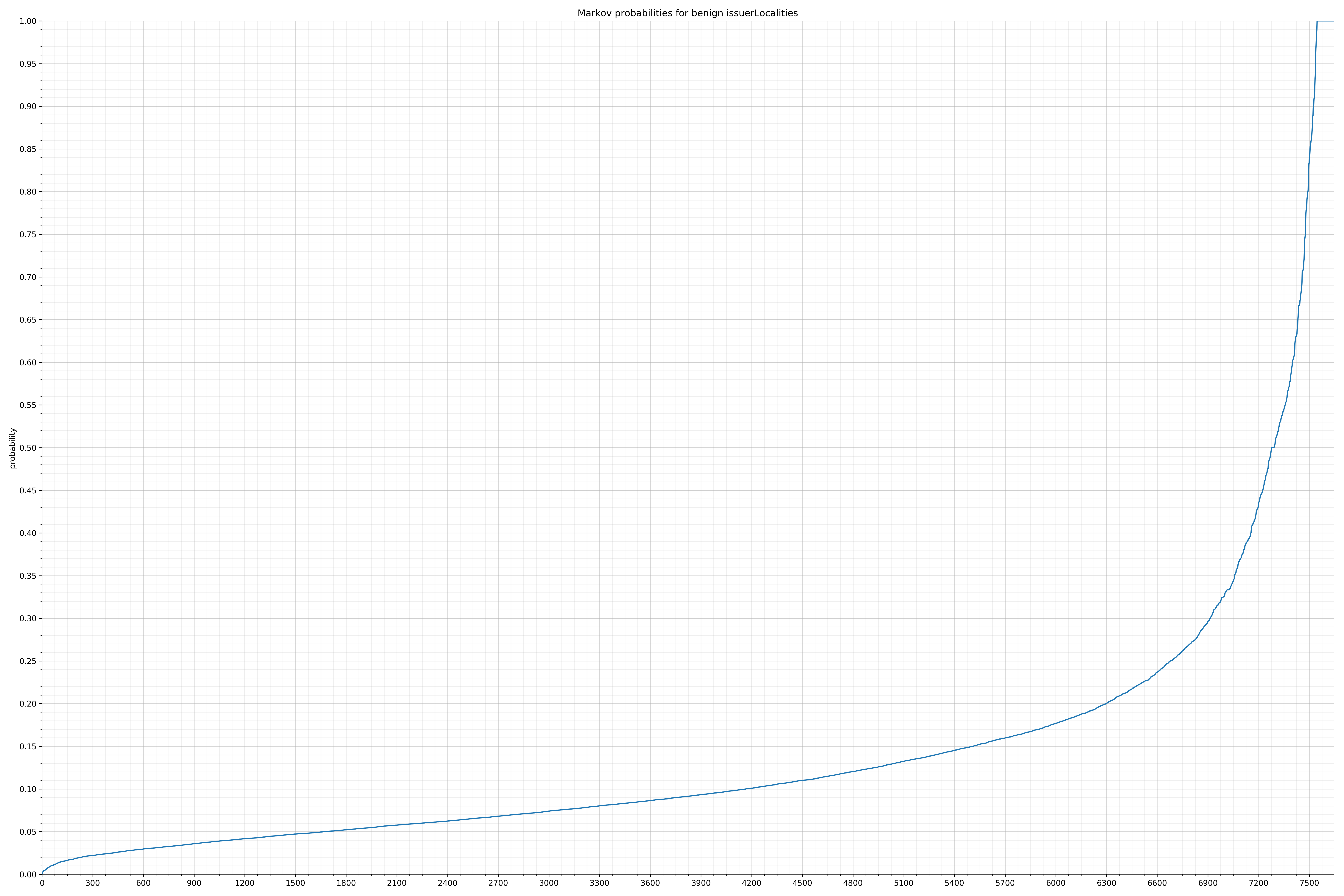
- issuerLocalities - benign / malicious
- issuerOrganizationalUnits - benign / malicious
- issuerOrganizations - benign / malicious
- issuerStateNames - benign / malicious
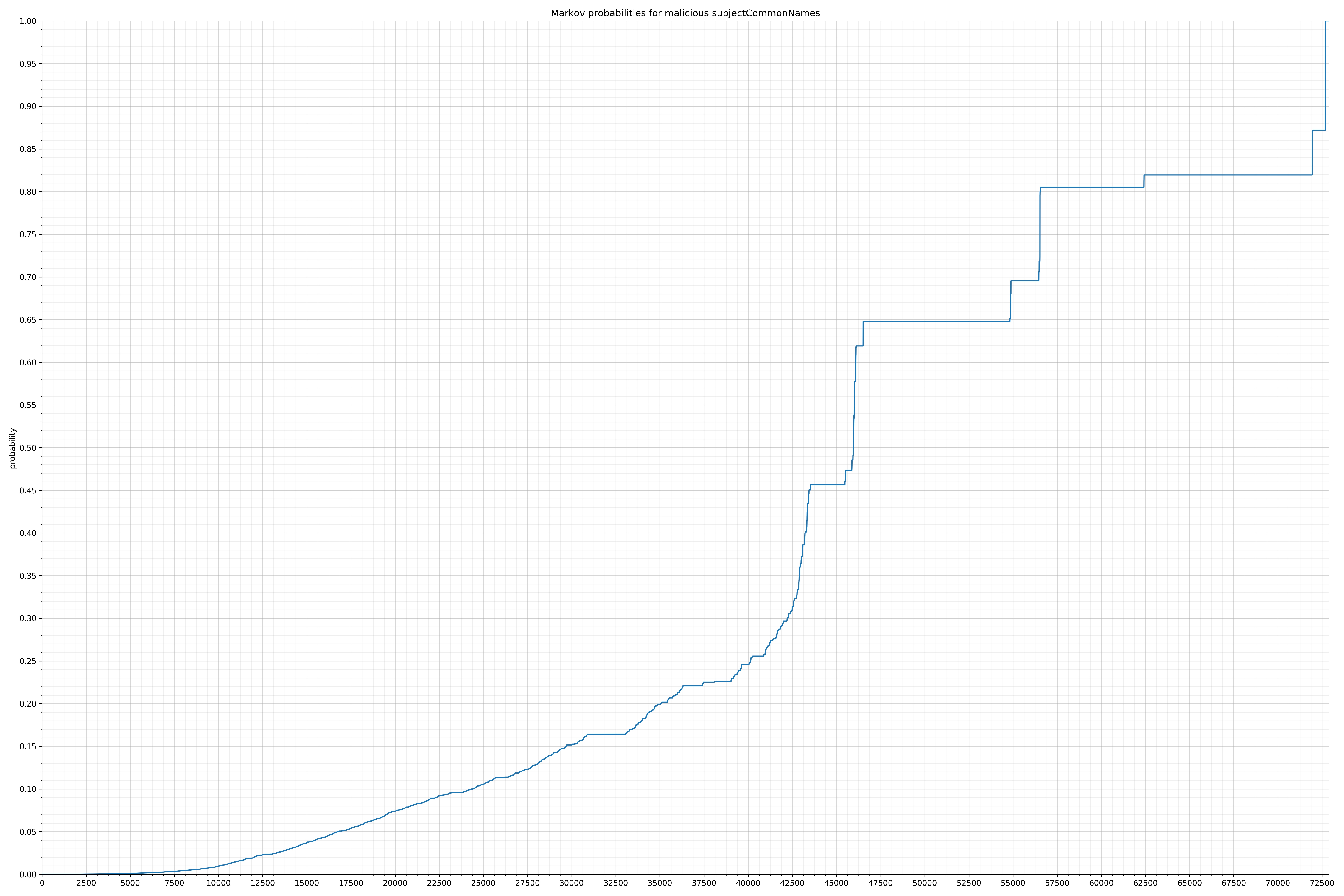
- subjectCommonNames - benign / malicious
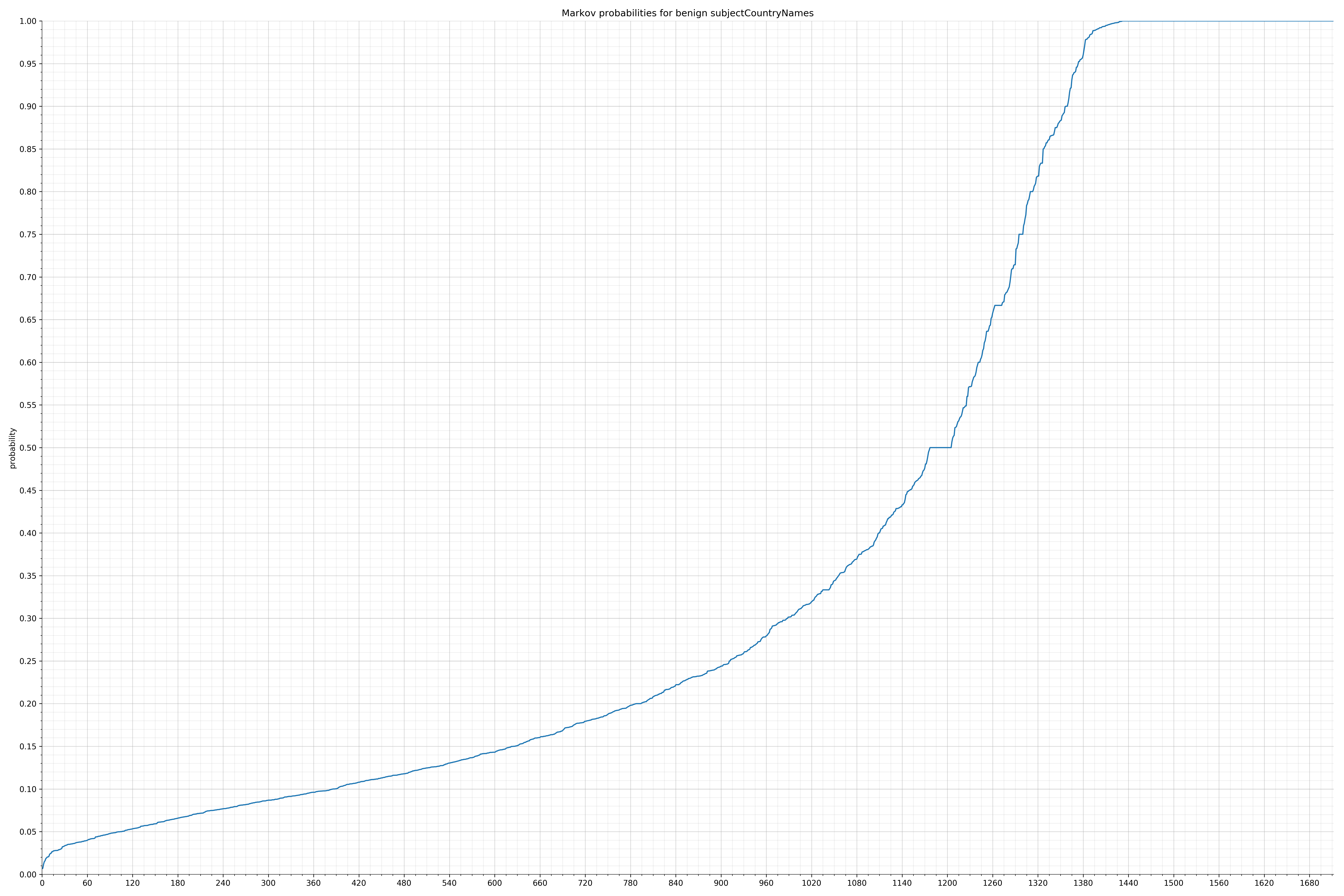
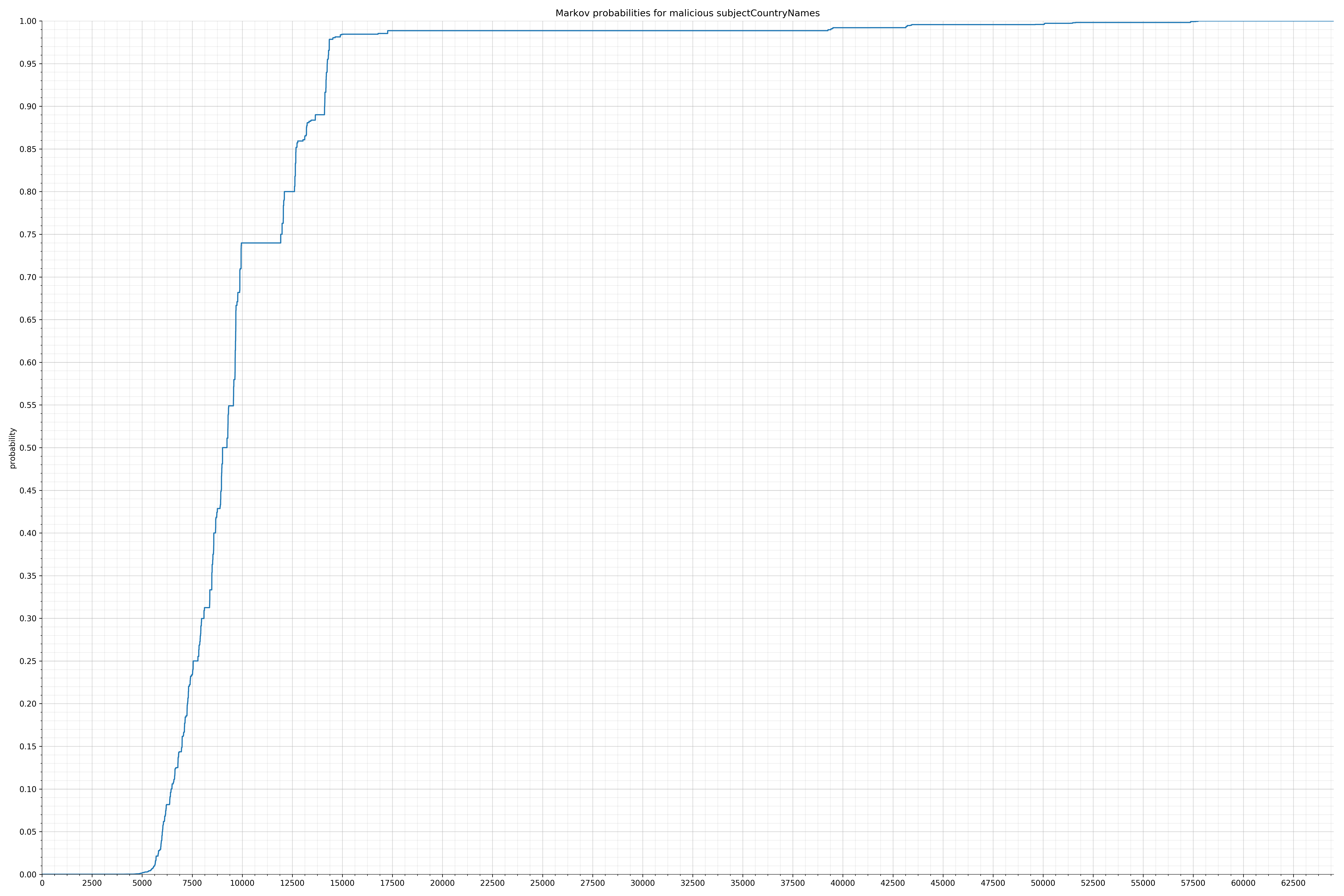
- subjectCountryNames - benign / malicious
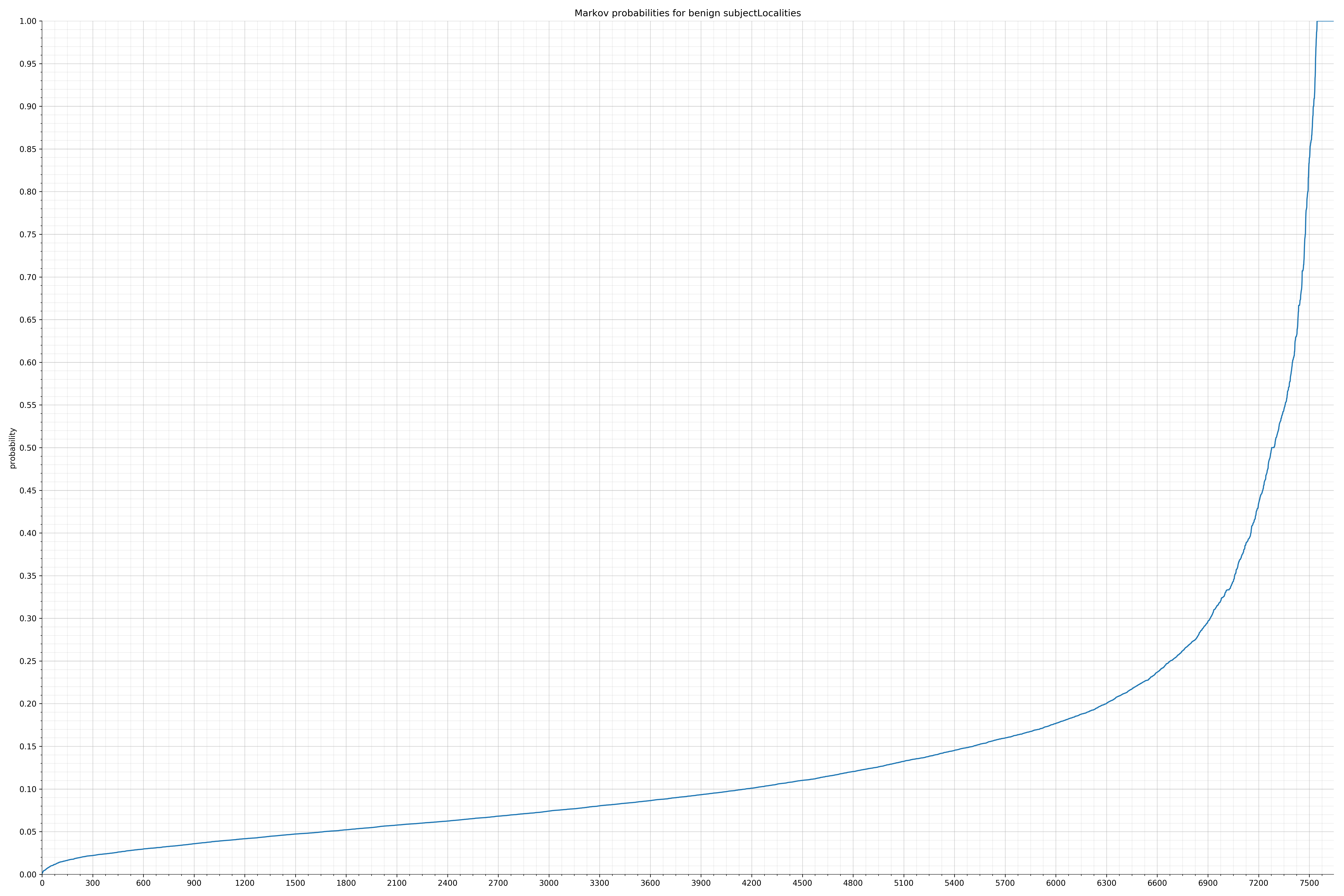
- subjectLocalities - benign / malicious
- subjectOrganizationalUnits - benign / malicious
- subjectOrganizations - benign / malicious
- subjectStateNames - benign / malicious
{kind=link}
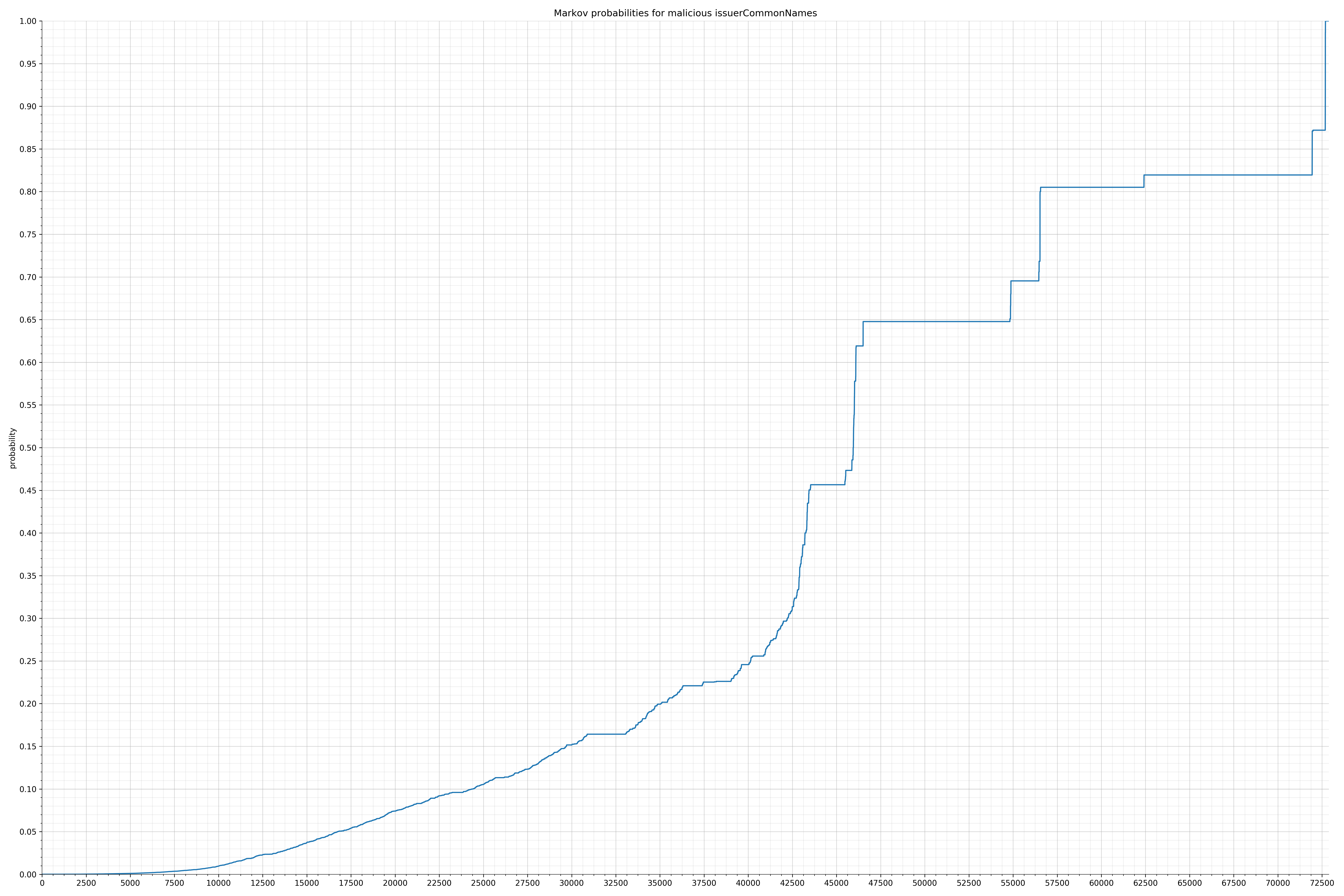{kind=link}
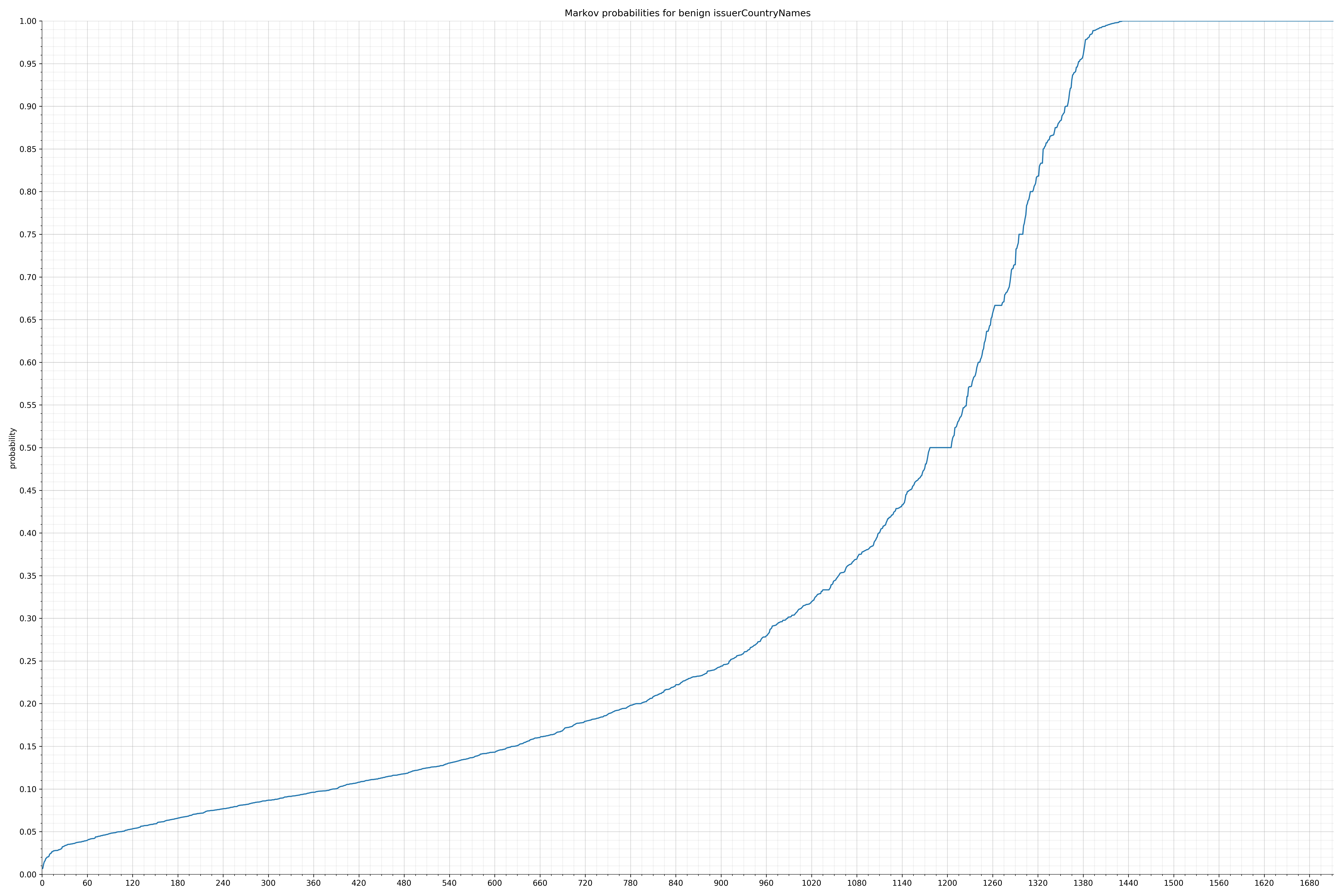{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comparing the Graphs
Let’s look at a specific example. One of the largest collections of strings were the string literals. These were all the strings that occurred in code. So in the case of String message = "hello,world!";, the string literal is hello,world!.
Below is the probability distribution of benign strings:
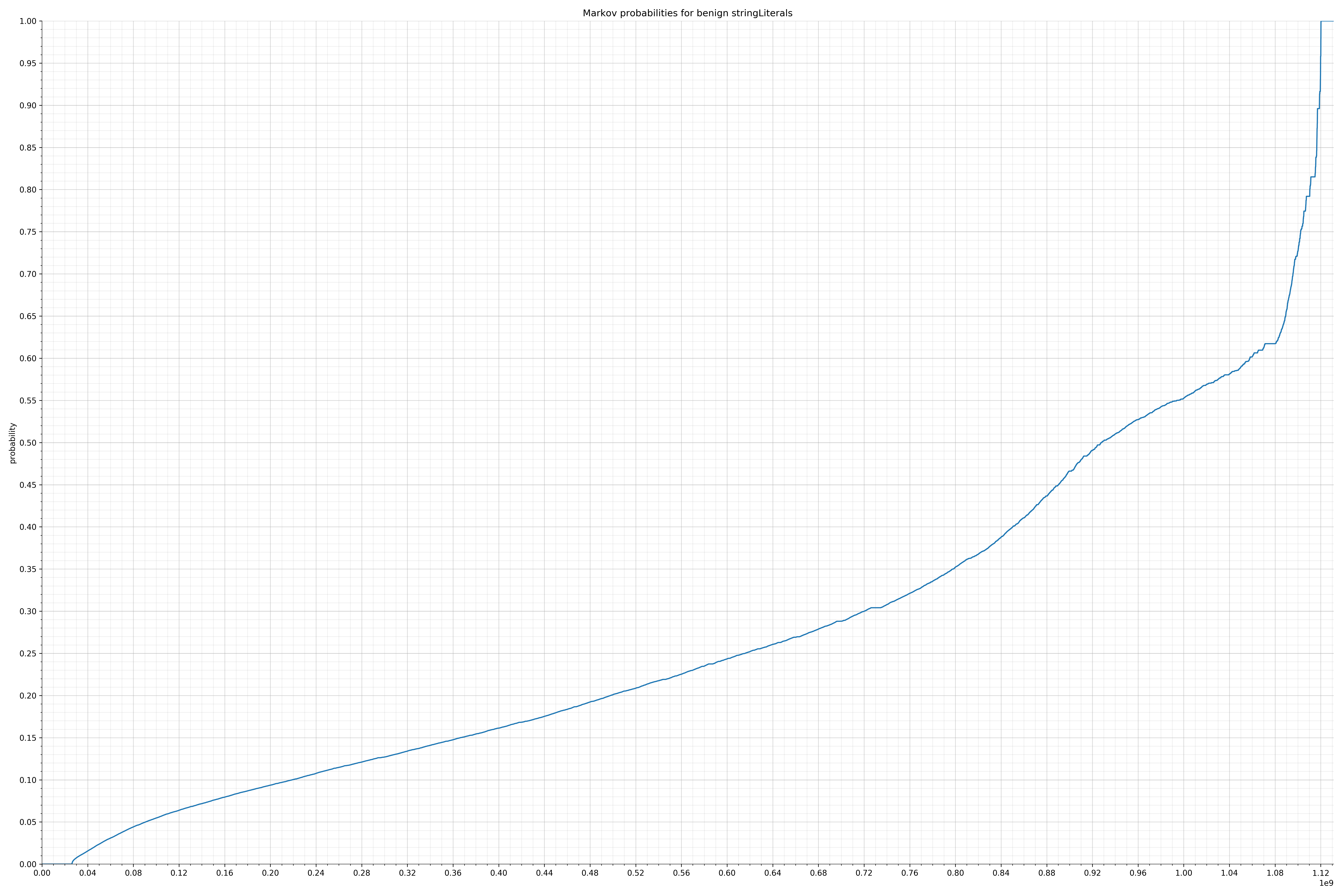
Below is the probability distribution of malicious strings:
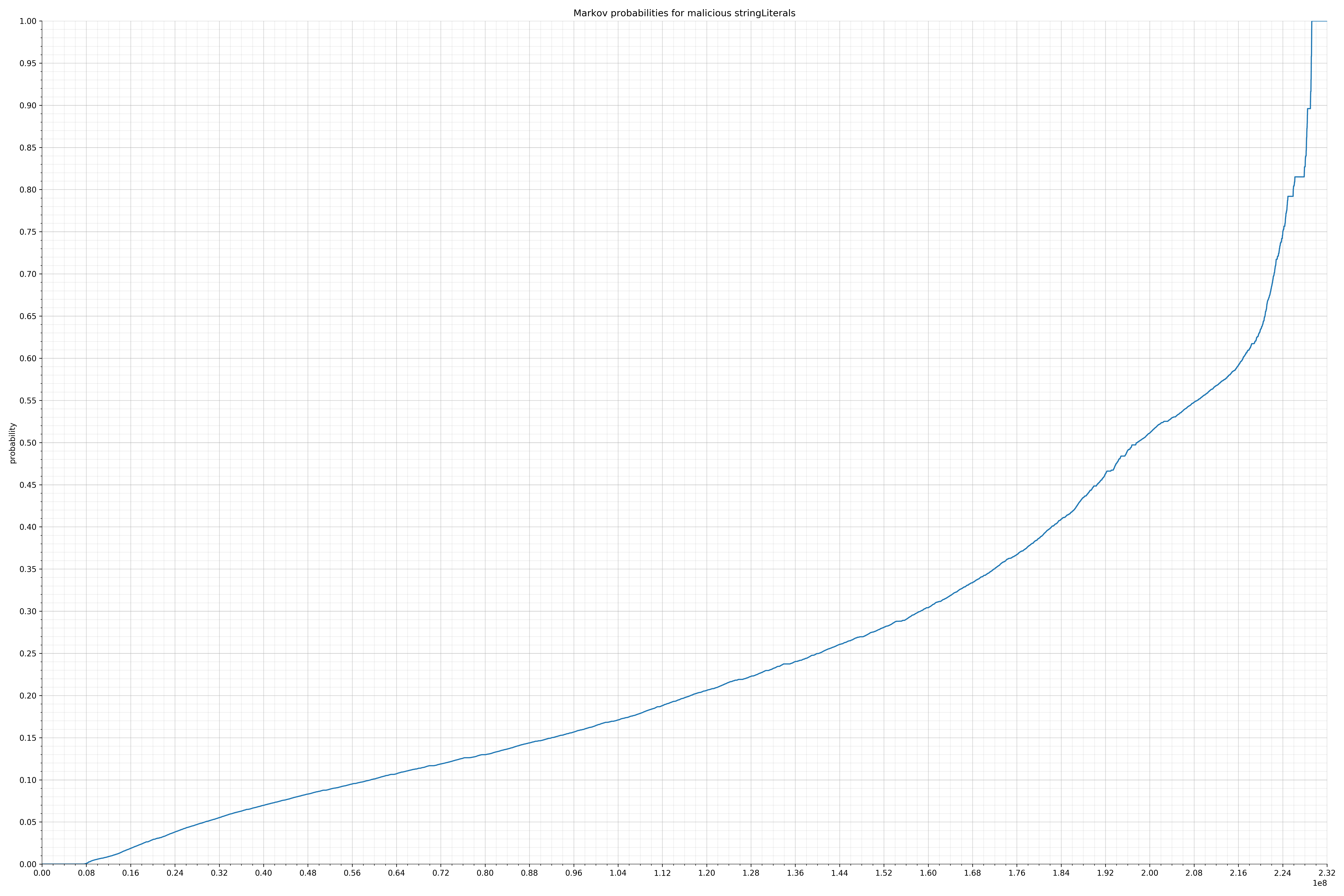
Notice the scale along the x-axis is different between the two graphs, but also note this isn’t as important as the general shape.
In the benign graph, strings are generally of a higher probability, especially at the lower end between 0.01 and 0.05 probability. This would indicate that adding this information to the model would improve model performance.
To add this information as a feature, I collected the probabilities of each string and put them into different bins. For example, for every string with a probability <= 0.01, I incremented the count of strings in the “probability 0.01” bin. The bins were:
1 | double[] bins = new double[]{ |
Notice that bins were more numerous in the lower probabilities to better capture the difference in observed distribution between the two classes (malicious / benign). Similar bin distributions were made for other string categories.
Results and Conclusion
By incorporating Markov features, model performance was fairly improved. Below are the “v1” model scores from a 10-fold cross validation using the top 10,000 features:
1 | recall: 0.938063119746 |
Below are the “v2” model scores measured in the same way:
1 | recall: 0.958403081067 |
I regard this as pretty good because every percentage point over 90% is difficult. Also note that these model performance scores are not using the optimal algorithm. I just threw the top 10,000 features into an ExtraTreesClassifier because it’s fast and fairly good. I wasn’t interested in best possible score, only relative improvements. Using a single, well-tuned model, and smarter feature selection, performance reaches 99%.
But 99% is still relatively poor performance for anti-virus, especially for precision, because false positives are so bad. I think the reason for the poor performance is because the malicious test set included adware and injected malware. Adware apps are difficult to distinguish statically and it’s even hard with skilled, manual analysis. Usually, it can only be known by behavioral analysis, i.e. does running this app cause many “annoying” ads to be displayed. By focusing the data set (i.e. cherry picking) more overtly malicious apps, model performance may get a lot better.
So-called injected malware is an otherwise benign app which has had malicious code injected into it. This is uniquely easy for Android malware authors due to the ease of app disassembly and reassembly. Perhaps unsurprisingly, the top features in Judge’s model are from APKiD which can fingerprint the compiler as a proxy for if an app has had code injected into it. This type of malware is also difficult to detect because usually most of the code is legitimate and this means features will reflect a mostly legitimate app.
In any case, further experimentation need to be done to decide which class of malware is most often missed. Once this is known, more features should be added to specifically address that type of malware.
Another remediating factor to consider with using this model is that any real anti-virus solution will be able to generally white list several types of apps to greatly reduce the impact of false positives. For example, an anti-virus company could record which signatures are most common and whitelist all of them. This would preclude the possibility of false positive detections of any popular or system apps.
Future Work
This experiment took two days to run and most of the time was spent extracting features. Also, during that time, my main desktop was booted into Linux and was unavailable for gaming, which was a huge drag. It should be possible to use a smaller data set to reduce iteration time. Maybe I could try 20-50 thousand rather than 180 thousand. samples.
Markov tokenization and n-gram selection can also be adjusted. It’s not clear if bigrams are ideal here. Trigrams may be better, or maybe 1-grams. Maybe it would be better to tokenize string literals only on spaces rather than spacing and punctuation since a lot of obfuscated strings are heavy on punctuation, and it would be good to capture that.
Learning done on the Markov features is probably quite sensitive to how the bins are defined. It may be good to add more bins in the upper ranges, or perhaps even more bins in the lower ranges. Once there are a few data points for performance, it should be possible to algorithmically determine bin sizes and automate some of the guess work. This would make ongoing model updates easier.
It may be useful to filter out commonly occurring classes. Most apps are bloated with common libraries, and by filtering them, the features would more accurately reflect what’s unique to each app. I’ve already created the fingerprinting code, which I’ll write about in a later post. My concern with this is that it’ll require more work to maintain a list of common classes since major libraries are numerous and change frequently.
Reference Data
I’m a big believer in sharing data so people can play with it themselves. Below are links to most of the data for these experiments:
These are compressed JSON files which should be easy to inspect and understand. String counts were recorded rather than strings because the Markov chains were trained by adding each string to the chain for each time it was counted. So if a string was seen 100 times, the Markov chain would have that string added 100 times.
Here’s some example code to deserialize the Markov model. This assumes it’s part of the Jar as a resource.
1 | InputStream is = MarkovLoader.class.getResourceAsStream("/markov_chains.obj"); |